Cross Validation#
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set_theme()
import numpy as np
import pandas as pd
from sklearn import preprocessing, pipeline, model_selection, linear_model, mixture
import warnings
warnings.filterwarnings('ignore')
Model Selection With Cross Validation#
Recall that there are three main types of learning:
Learning model parameters from data.
Learning to predict new data (unsupervised learning).
Learning to predict target features in new data (supervised learning).
All three types of learning require an assumed model with associated parameters, and predicting new data is only possible after learning model parameters from old data.
Since all types of learning assume a model, they must all solve the meta-problem of comparing competing models. The Bayesian evidence \(P(D\mid M)\) is our primary quantitative tool for comparing how well different models explain the same data. When we are primarily interested in a model’s ability to generalize and predict new data, cross validation is a useful alternative.
Train vs. Validate vs. Test Data#
During an ML model development and evaluation, various types of data are utilized. Below, we review these types of data, their purpose and the differences between each in how they are used.

Training Dataset: The sample of data used to fit the model.
The actual dataset that we use to train the ML model under development (weights and biases in the case of a Neural Network). The model sees and learns from this data. Training data are collections of examples or samples that are used to “teach” or “train” the model. The model uses a training data set to understand the patterns and relationships within the data, thereby learning to make predictions or decisions without being explicitly programmed to perform a specific task.
Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset (i.e. a “trained model”) while tuning model hyperparameters. The evaluation becomes more biased as more skill on the validation dataset is incorporated into the model configuration.
It is still possible to tune and control the model at this stage. Working on validation data is used to assess the model performance and fine-tune the parameters of the model. This becomes an iterative process wherein the model learns from the training data and is then validated and fine-tuned on the validation set. A validation dataset tells us how well the model is learning and adapting, allowing for adjustments and optimizations to be made to the model’s parameters or hyperparameters before it’s finally put to the test. So the validation set affects a model, but only indirectly.
Note that not all models require validation sets. Some experts consider that ML models with no hyperparameters or those that do not have tuning options do not need a validation set. Still, in most practical applications, validation sets play a crucial role in ensuring the model’s robustness and performance.
Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
The Test dataset provides the gold standard used to evaluate the model. It is only used once a model is completely trained (using the train and validation sets). It is a separate sample, an unseen data set, to provide an unbiased final evaluation of a model. Its primary purpose is to offer a fair and final assessment of how the model would perform when it encounters new data in a live, operational environment.
The test set is generally what is used to evaluate competing models (For example on many Kaggle competitions, the validation set is released initially along with the training set and the actual test set is only released when the competition is about to close, and it is the result of the the model on the Test set that decides the winner).
Many a times the validation set is used as the test set, but it is not good practice. The test set is generally well curated. It contains carefully sampled data that spans the various classes that the model would face, when used in the real world on data it has never seen before. The inputs in the test data are similar to the previous stages but not the same data.
Cross Validation (CV) Process#
Cross validation is a process that provides the ability to estimate model performance on unseen data not used while training. It is a systematic process that can involve tuning the model hyperparameters, testing different properties of the overall datasets, and iterating the training process. There are many variations of the CV process - we will study primarily the K-folds method in this lecture. We will show some examples using random sampling (called “folds”) of these types of data to illustrate the process. For simplicity, we will focus on the test and train data and not consider validation data explicitly in the following.
The figure below summarizes the data splitting and process:

The basic idea of cross validation is to:
split the observed data into separate training and test datasets
learn the model from the training dataset
measure the model’s ability to predict the test dataset
repeat the steps above with different splits (“folds”) and combine the results.
Overfitting and Generalization#
Generate some data consisting of 2D points along the path of a projectile, where \(x\) is measured with negligible error and \(y\) has a known error \(\sigma_y\):
xlo, xhi = 0., 1.
poly_coefs = np.array([-1., 2., -1.])
f = lambda X: np.dot(poly_coefs, [X ** 0, X ** 1, X ** 2])
sigma_y = 0.2
def generate(N, seed=123):
gen = np.random.RandomState(seed=seed)
X = gen.uniform(xlo, xhi, size=N)
y = f(X) + gen.normal(scale=sigma_y, size=N)
return X, y
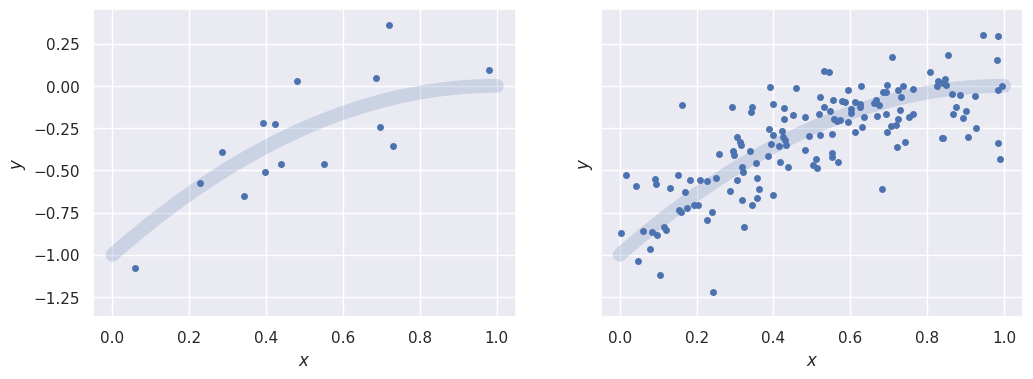
Compare results with different numbers of samples from the same model:
Xa, ya = generate(N=15)
Xb, yb = generate(N=150)
def plotXy(X, y, ax=None, *fits):
ax = ax or plt.gca()
ax.scatter(X, y, s=25, lw=0)
x_grid = np.linspace(xlo, xhi, 100)
ax.plot(x_grid, f(np.array(x_grid)), '-', lw=10, alpha=0.2)
for fit in fits:
y_fit = fit.predict(x_grid.reshape(-1, 1))
ax.plot(x_grid, y_fit, lw=2, alpha=1)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ylo, yhi = np.percentile(y, (0, 100))
dy = yhi - ylo
ax.set_ylim(ylo - 0.1 * dy, yhi + 0.1 * dy)
_, ax = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
plotXy(Xa, ya, ax[0])
plotXy(Xb, yb, ax[1])
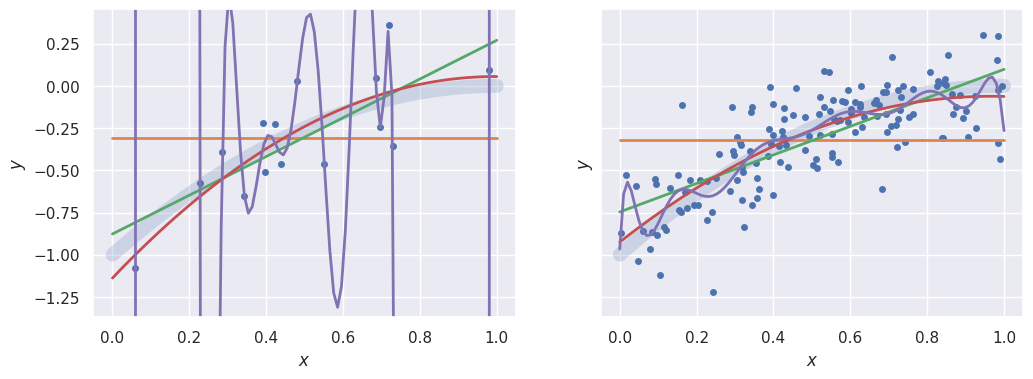
The family of competing models we consider are polynomials of different degrees \(P\),
each with \(P+1\) parameters. The true model that the datasets were generated from have \(P=2\).
Use sklearn LinearRegression to implement this fit after expanding the features with PolynomialFeatures,
and combining the preprocessing and regression steps into a Pipeline:
def poly_fit(X, y, degree):
degree_is_zero = (degree == 0)
model = pipeline.Pipeline([
('poly', preprocessing.PolynomialFeatures(degree=degree, include_bias=degree_is_zero)),
('linear', linear_model.LinearRegression(fit_intercept=not degree_is_zero))])
return model.fit(X.reshape(-1, 1), y)
Compare fits with \(P = 0, 1, 2, 14\) to each dataset. Note that \(P=14\) is an extreme case of overfitting to the smaller dataset, with the model passing exactly through each sample with large oscillations between them. Similarly, \(P=1\) underfits the larger dataset:
_, ax = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
plotXy(Xa, ya, ax[0], poly_fit(Xa, ya, 0), poly_fit(Xa, ya, 1), poly_fit(Xa, ya, 2), poly_fit(Xa, ya, 14))
plotXy(Xb, yb, ax[1], poly_fit(Xb, yb, 0), poly_fit(Xb, yb, 1), poly_fit(Xb, yb, 2), poly_fit(Xb, yb, 14))
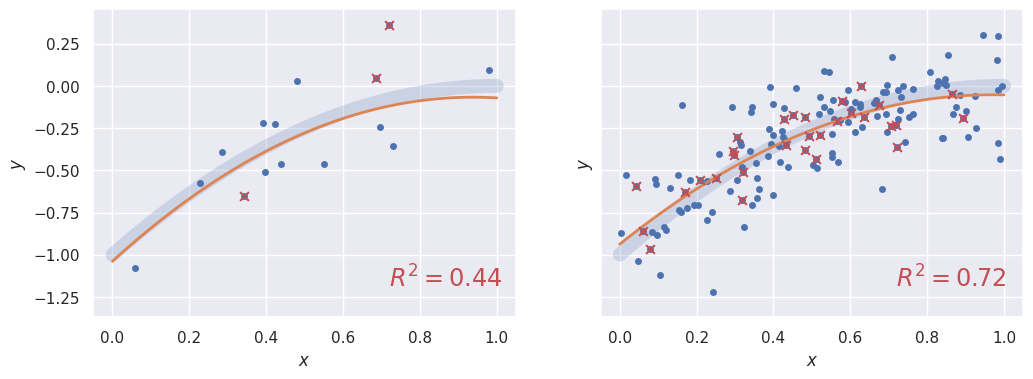
Train-Test Split#
The train_test_split function picks a random fraction of the observed data to hold back when learning the model and then use for latest testing.
Note that since train/test splitting involves random numbers, you will need to pass around a random state object for reproducible results.
The plots below show 20% of the data reserved for testing (red points) with a \(P=2\) fit to the training data superimposed. The primary sklearn test metric for regression problems is the coefficient of determination \(R^2\), for which the goal is \(R^2 = 1\):
def train_test_split(X, y, degree, test_fraction=0.2, ax=None, seed=123):
gen = np.random.RandomState(seed=seed)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=test_fraction, random_state=gen)
train_fit = poly_fit(X_train, y_train, degree)
plotXy(X, y, ax, train_fit)
test_R2 = train_fit.score(X_test.reshape(-1, 1), y_test)
ax.scatter(X_test, y_test, marker='x', color='r', s=40, zorder=10)
ax.text(0.7, 0.1, '$R^2={:.2f}$'.format(test_R2), transform=ax.transAxes, fontsize='x-large', color='r')
_, ax = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
train_test_split(Xa, ya, 2, ax=ax[0])
train_test_split(Xb, yb, 2, ax=ax[1])
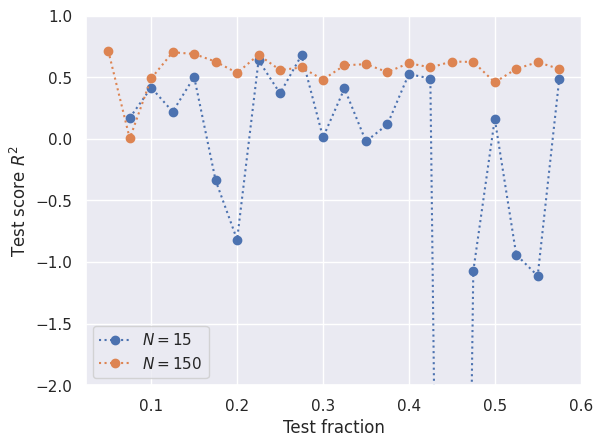
There is no rigorous procedure for setting an optimum test fraction, and anything between 0.1 and 0.5 would be reasonable (and the sklearn default is 0.25). A larger test fraction improves the reliability of the test metric but decreases the reliability of the model being tested. As always, more data always helps and reduces your sensitivity to the training fraction.
def test_fraction_scan(degree=2, seed=123):
gen = np.random.RandomState(seed=seed)
test_fractions = np.arange(0.05, 0.6, 0.025)
R2 = np.empty((2, len(test_fractions)))
for i, test_fraction in enumerate(test_fractions):
for j, (X, y) in enumerate(((Xa, ya), (Xb, yb))):
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=test_fraction, random_state=gen)
fit = poly_fit(X_train, y_train, degree)
R2[j, i] = fit.score(X_test.reshape(-1, 1), y_test)
plt.plot(test_fractions, R2[0], 'o:', label='$N = {}$'.format(len(ya)))
plt.plot(test_fractions, R2[1], 'o:', label='$N = {}$'.format(len(yb)))
plt.xlabel('Test fraction')
plt.ylabel('Test score $R^2$')
plt.ylim(-2, 1)
plt.legend()
test_fraction_scan()
K-Folding#
Cross validation goes beyond a simple train-test split by repeating the split multiple times and combining the (correlated) results. There are different strategies for picking the different splits, but K-folding is a good all-around choice:
Specify the number \(k\) of splits (folds) to use.
The data is split into \(k\) (almost) equal independent subsets.
Each subset is used for testing once, with the remaining subsets used for training.
The result is \(k\) different train-test splits using a test fraction \(1/k\). For example, with \(N=10\) samples and \(k=3\) folds, the subsets are:
kfold = model_selection.KFold(n_splits=3)
[tuple(split[1]) for split in kfold.split(range(10))]
[(np.int64(0), np.int64(1), np.int64(2), np.int64(3)),
(np.int64(4), np.int64(5), np.int64(6)),
(np.int64(7), np.int64(8), np.int64(9))]
The cross_validate function automates the k-folding and scoring process, and outputs both train and test \(R^2\) scores, as well as CPU times, for each split:
def cross_validate(X, y, degree, n_splits):
model = pipeline.Pipeline([
('poly', preprocessing.PolynomialFeatures(degree=degree)),
('linear', linear_model.LinearRegression(fit_intercept=True))])
kfold = model_selection.KFold(n_splits=n_splits)
scores = model_selection.cross_validate(
model, X.reshape(-1, 1), y, cv=kfold, return_train_score=True)
index = [tuple(split[1]) for split in kfold.split(X.reshape(-1, 1))]
return pd.DataFrame(scores, index=index)
cross_validate(Xa, ya, degree=2, n_splits=3)
| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| (0, 1, 2, 3, 4) | 0.000966 | 0.000274 | 0.404038 | 0.731105 |
| (5, 6, 7, 8, 9) | 0.000413 | 0.000196 | -2.232860 | 0.632223 |
| (10, 11, 12, 13, 14) | 0.000348 | 0.000321 | -0.352504 | 0.518438 |
With enough data, you can use a large number of K-folds but remember that they are highly correlated so you are not increasing the useful information as much as you might think. The sklearn default number of splits is 3.
cross_validate(Xb, yb, degree=2, n_splits=15)
| fit_time | score_time | test_score | train_score | |
|---|---|---|---|---|
| (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) | 0.000663 | 0.000248 | 0.574221 | 0.613270 |
| (10, 11, 12, 13, 14, 15, 16, 17, 18, 19) | 0.000382 | 0.000189 | 0.644016 | 0.608664 |
| (20, 21, 22, 23, 24, 25, 26, 27, 28, 29) | 0.000340 | 0.000177 | 0.559857 | 0.614704 |
| (30, 31, 32, 33, 34, 35, 36, 37, 38, 39) | 0.000325 | 0.000174 | 0.382087 | 0.619587 |
| (40, 41, 42, 43, 44, 45, 46, 47, 48, 49) | 0.000316 | 0.000171 | 0.741344 | 0.601154 |
| (50, 51, 52, 53, 54, 55, 56, 57, 58, 59) | 0.000310 | 0.000165 | 0.415899 | 0.625590 |
| (60, 61, 62, 63, 64, 65, 66, 67, 68, 69) | 0.000314 | 0.000164 | 0.675124 | 0.601310 |
| (70, 71, 72, 73, 74, 75, 76, 77, 78, 79) | 0.000304 | 0.000162 | 0.745460 | 0.599734 |
| (80, 81, 82, 83, 84, 85, 86, 87, 88, 89) | 0.000326 | 0.000169 | 0.366792 | 0.618551 |
| (90, 91, 92, 93, 94, 95, 96, 97, 98, 99) | 0.000308 | 0.000164 | 0.498276 | 0.614549 |
| (100, 101, 102, 103, 104, 105, 106, 107, 108, 109) | 0.000306 | 0.000162 | 0.752076 | 0.595514 |
| (110, 111, 112, 113, 114, 115, 116, 117, 118, 119) | 0.000297 | 0.000161 | 0.604196 | 0.610233 |
| (120, 121, 122, 123, 124, 125, 126, 127, 128, 129) | 0.000299 | 0.000161 | -0.292603 | 0.630345 |
| (130, 131, 132, 133, 134, 135, 136, 137, 138, 139) | 0.000303 | 0.000158 | 0.529028 | 0.616538 |
| (140, 141, 142, 143, 144, 145, 146, 147, 148, 149) | 0.000297 | 0.000164 | 0.513520 | 0.619319 |
Hyperparameter Grid Search#
The GridSearchCV function puts all the pieces together to scan a grid of one or more hyperparameters for a family of models. For example, the polynomial degree \(P\) corresponds to a pipeline poly__degree parameter, which we vary from 0 to 5 below.
def cv_summary(cv):
"""Summarize the results from a GridSearchCV fit.
Summarize a cross-validation grid search in a pandas DataFrame with the
following transformations of the full results:
- Remove all columns with timing measurements.
- Remove the 'param_' prefix from column names.
- Remove the '_score' suffix from column names.
- Round scores to 3 decimal places.
If the parameter grid is 1D, then this function also plots the test
and training R2 scores versus the parameter.
Parameters
----------
cv : sklearn.model_selection.GridSearchCV
Instance of a GridSearchCV object that has been fit to some data.
Returns
-------
pandas.DataFrame
Summary table of cross-validation results.
"""
# Look up the list of parameters used in the grid.
params = list(cv.cv_results_['params'][0].keys())
# Index results by the test score rank.
index = cv.cv_results_['rank_test_score']
df = pd.DataFrame(cv.cv_results_, index=index).drop(columns=['params', 'rank_test_score'])
# Remove columns that measure running time.
df = df.drop(columns=[n for n in df.columns.values if n.endswith('_time')])
# Remove param_ prefix from column names.
df = df.rename(lambda n: n[6:] if n.startswith('param_') else n, axis='columns')
# Remove _score suffix from column names.
df = df.rename(lambda n: n[:-6] if n.endswith('_score') else n, axis='columns')
if len(params) == 1:
# Plot the test and training scores vs the grid parameter when there is only one.
plt.plot(df[params[0]], df['mean_train'], 'o:', label='train')
plt.plot(df[params[0]], df['mean_test'], 'o-', label='test')
plt.legend(fontsize='x-large')
plt.xlabel('Hyperparameter value')
plt.ylabel('Score $R^2$')
plt.ylim(max(-2, np.min(df['mean_test'])), 1)
return df.sort_index().round(3)
def compare_models(X, y, max_degree=5, n_splits=3, seed=123):
hyper_grid = {'poly__degree': range(max_degree + 1)}
hyper_model = pipeline.Pipeline([
('poly', preprocessing.PolynomialFeatures()),
('linear', linear_model.LinearRegression(fit_intercept=True))])
kfold = model_selection.KFold(n_splits=n_splits)
cv = model_selection.GridSearchCV(hyper_model, hyper_grid, cv=kfold, return_train_score=True)
cv.fit(X.reshape(-1, 1), y)
return cv_summary(cv)
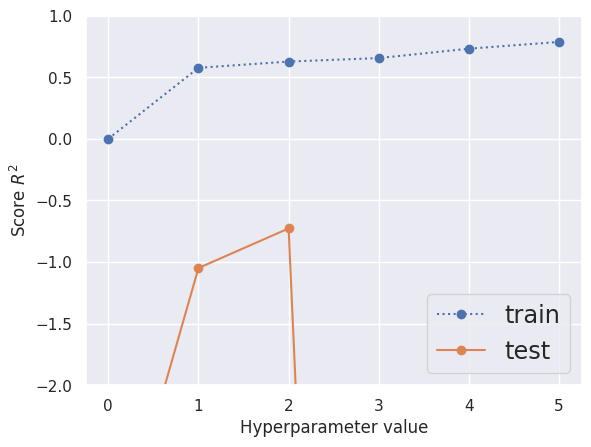
With a small dataset, a polynomial fit is very prone to overfitting and the training score continues to rise as \(P\) increases. However, only the \(P=1\) and \(P=2\) models look at all promising on the test data, but are still worse than guessing the average \(y\) value (which always has \(R^2=0\)):
compare_models(Xa, ya)
| poly__degree | split0_test | split1_test | split2_test | mean_test | std_test | split0_train | split1_train | split2_train | mean_train | std_train | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0.404 | -2.233 | -0.353 | -0.727 | 1.109 | 0.731 | 0.632 | 0.518 | 0.627 | 0.087 |
| 2 | 1 | 0.474 | -2.819 | -0.801 | -1.049 | 1.356 | 0.621 | 0.628 | 0.481 | 0.577 | 0.068 |
| 3 | 0 | -0.048 | -7.549 | -3.226 | -3.608 | 3.074 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 4 | 4 | -1.743 | -5.019 | -28.006 | -11.589 | 11.685 | 0.857 | 0.714 | 0.625 | 0.732 | 0.095 |
| 5 | 3 | 0.408 | -51.581 | -0.324 | -17.166 | 24.337 | 0.740 | 0.708 | 0.518 | 0.656 | 0.098 |
| 6 | 5 | -0.837 | -316.856 | -157.921 | -158.538 | 129.015 | 0.895 | 0.716 | 0.749 | 0.787 | 0.077 |
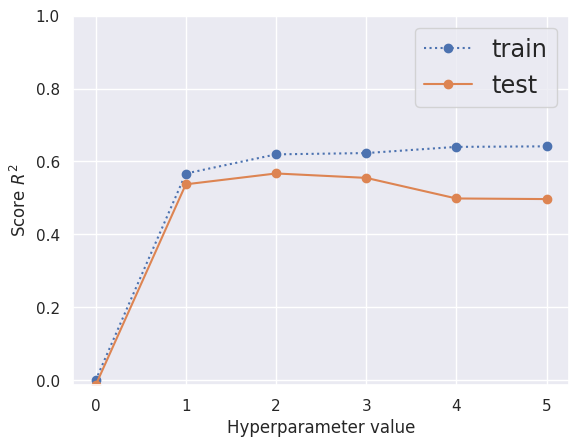
With a larger dataset, the training score is stable over a wide range of \(P\ge 1\) and the test score decreases very slowly. You could make a case for either \(P=1\) (less overfitting) or \(P=2\) (better test score) from the graph below:
compare_models(Xb, yb)
| poly__degree | split0_test | split1_test | split2_test | mean_test | std_test | split0_train | split1_train | split2_train | mean_train | std_train | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0.593 | 0.600 | 0.509 | 0.567 | 0.041 | 0.610 | 0.611 | 0.638 | 0.620 | 0.013 |
| 2 | 3 | 0.563 | 0.590 | 0.512 | 0.555 | 0.032 | 0.619 | 0.612 | 0.639 | 0.623 | 0.011 |
| 3 | 1 | 0.607 | 0.590 | 0.415 | 0.537 | 0.087 | 0.536 | 0.540 | 0.625 | 0.567 | 0.041 |
| 4 | 4 | 0.575 | 0.584 | 0.337 | 0.499 | 0.114 | 0.620 | 0.612 | 0.688 | 0.640 | 0.034 |
| 5 | 5 | 0.569 | 0.586 | 0.336 | 0.497 | 0.114 | 0.623 | 0.612 | 0.689 | 0.642 | 0.034 |
| 6 | 0 | -0.017 | -0.023 | -0.001 | -0.014 | 0.009 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Comparison with Bayesian Evidence Using PyMC#
The function below estimates the Bayesian evidence for the data \(D=(X,y)\) given a polynomial model of degree \(P\), using the same MCMC techniques we saw earlier but implemented within the PyMC framework. PyMC is a probabilistic programming library for Python that allows users to build Bayesian models with a simple Python API and fit them using Markov chain Monte Carlo (MCMC) methods. The evidence calculation requires an additional ingredient that we never specified for cross validation: a prior on the \(P + 1\) polynomial coefficients, which has a similar effect to a regularization term in an sklearn linear regression. We adopt a Gaussian prior on each coefficient with the same scale, chosen to be large enough that the likelihood will dominate the posterior.
The evidence calculation method via the GMM-based approach implemented in estimate_log_evidence below, is mathematically sound as an approximate method for estimating the log marginal likelihood (log evidence).
The logic follows the identity:
where \(\log P(D, \Theta|M)\) is the \(\mathbf{\text{log joint probability}}\) (\(\log \text{likelihood} + \log \text{prior}\)) and \(\log P(\Theta|D, M)\) is the \(\mathbf{\text{log posterior density}}\).
The code implements a function, calculate_evidence, which offers several methods for estimating the log marginal likelihood (\(\log Z = \log P(D|M)\)). The key method for direct evidence estimation is the Gaussian Mixture Model (GMM) approximation, which we encountered before.
The PyMC Model and MCMC Sampling#
Model Definition: A polynomial regression model of degree \(d\) is defined in PyMC, where the number of parameters is \(P = d+1\).
Prior: All coefficients are assigned a Gaussian prior \(\text{Normal}(0, \sigma_{\text{coef}})\).
Likelihood: The observed data \(y_{\text{data}}\) is modeled as \(\text{Normal}(\mu, \sigma_y)\), where \(\mu\) is the polynomial fit (\(\mathbf{X} \cdot \Theta\)) and \(\sigma_y\) is the known observation standard deviation.
Sampling: NUTS (or HMC) MCMC sampling is performed to generate samples from the posterior distribution \(P(\Theta|D, M)\). These samples are extracted as
coef_samples(shape: \(N_{\text{samples}} \times P\)).
GMM-Based Log Evidence Calculation#
The estimate_log_evidence function takes the MCMC samples and a pre-evaluated grid to estimate \(\log Z\).
A. Log Joint Calculation (The Numerator)#
The log joint probability \(\log P(D, \Theta|M)\) is calculated on a parameter grid (\(\Theta_{\text{grid}}\)) derived from the MCMC samples.
Grid Construction (
create_param_grid): A dense grid (\(\Theta_{\text{grid}}\)) is constructed using percentiles of the MCMC samples. This efficiently covers the high-probability region of the parameter space.Log Joint Evaluation: The log joint probability (
log_numerator) is calculated for every point on the grid outside the PyMC model using closed-form expressions for the prior and likelihood:log_prior: Sum of the log PDFs of the independent Gaussian priors for \(\Theta\).log_lik: Sum of the log PDFs of the Gaussian likelihood evaluated at the grid parameters.log_numerator=log_prior+log_lik.
B. Log Posterior Estimation (The Denominator)#
The log posterior density, \(\log P(\Theta|D, M)\), is approximated using a Gaussian Mixture Model (GMM).
GMM Fitting: A GMM is fitted to the MCMC samples (\(\Theta_{\text{samples}}\)). The GMM is trained on the distribution from which the samples were drawn, which is \(P(\Theta|D, M)\).
Density Evaluation: The GMM provides an estimate of the log posterior density (\(\mathbf{\text{use\_log\_density}}\)) at the selected grid points using
fit.score_samples.Optimization: The method iterates over a range of GMM components (\(1\) to \(\text{max\_components}\)). The number of components that minimizes the spread (inter-quantile range) of the \(\log Z\) estimates across the grid is chosen as the optimal one.
C. Final Estimate#
The estimate for \(\log Z\) is calculated for each grid point and optimal GMM component:
The final result is the median of these stable estimates, providing a robust approximation of the log evidence.
import numpy as np
import pymc as pm
import arviz as az
from typing import Union, Dict, Any
from scipy.stats import multivariate_normal
from sklearn import mixture
import matplotlib.pyplot as plt
import logging
import pymc as pm_version_check
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Check PyMC version
pymc_version = pm_version_check.__version__
if not pymc_version.startswith("5"):
logger.warning("This code is designed for PyMC 5.x. For PyMC 4.x, use `logp_dlogp` instead of `compile_logp` and `d2logp`. Contact support for the PyMC 4.x version.")
def create_param_grid(samples: np.ndarray, n_grid: int = 50) -> np.ndarray:
"""Create a parameter grid from posterior samples for GMM-based evidence estimation."""
samples = np.asarray(samples)
quantiles = np.linspace(0, 100, n_grid)
grid = [np.percentile(samples[:, j], quantiles) for j in range(samples.shape[1])]
mesh = np.meshgrid(*grid)
return np.stack([m.flatten() for m in mesh], axis=-1)
def estimate_log_evidence(
samples: np.ndarray,
param_grid: np.ndarray,
log_numerator: np.ndarray,
max_components: int = 5,
grid_fraction: float = 0.1,
plot: bool = False,
seed: int = 123
) -> float:
"""Estimate log evidence using Gaussian Mixture Model (GMM) approximation."""
samples = np.asarray(samples)
cut = np.percentile(log_numerator, 100. * (1 - grid_fraction))
use = np.where(log_numerator >= cut)[0]
use_grid = param_grid[use]
use_log_numerator = log_numerator[use]
rng = np.random.RandomState(seed)
log_evidence = np.empty((max_components, len(use)))
for i in range(max_components):
fit = mixture.GaussianMixture(n_components=i + 1, random_state=rng).fit(samples)
use_log_density = fit.score_samples(use_grid)
log_evidence[i] = use_log_numerator - use_log_density
lo, med, hi = np.percentile(log_evidence, (5, 50, 95), axis=-1)
spread = 0.5 * (hi - lo)
best = np.argmin(spread)
if plot:
plt.scatter(use_log_numerator, log_evidence[best], s=10, lw=0)
plt.xlabel(r'$\log P(D|\Theta,M) + \log P(\Theta|M)$')
plt.ylabel(r'$\log P(D|M)$')
plt.axhline(lo[best], ls='--', c='k', label='5th/95th percentiles')
plt.axhline(hi[best], ls='--', c='k')
plt.axhline(med[best], ls='-', c='k', label='Median')
plt.title(f'n_GMM={best+1}, logP(D|M)={med[best]:.3f}')
plt.legend()
plt.show()
return med[best]
def calculate_evidence(
Xdata: Union[np.ndarray, list],
ydata: Union[np.ndarray, list],
degree: int,
sigma_y: float = 1.0,
coef_sigma: float = 10.0,
n_mc: int = 1000,
n_grid: int = 50,
seed: int = 123,
method: str = "waic",
grid_fraction: float = 0.1,
plot: bool = False
) -> Dict[str, Any]:
"""
Fits a polynomial regression model using PyMC and calculates model evidence
approximations using various methods (WAIC, LOO, Laplace, GMM).
Parameters
----------
Xdata : np.ndarray or list
Input features (1D or 2D array of shape (n_samples,) or (n_samples, n_features)).
ydata : np.ndarray or list
Target values (1D array of shape (n_samples,)).
degree : int
Polynomial degree (non-negative).
sigma_y : float, optional
Standard deviation of observation noise (default: 1.0).
coef_sigma : float, optional
Standard deviation of prior on coefficients (default: 10.0).
n_mc : int, optional
Total number of MCMC samples (default: 2000).
n_grid : int, optional
Number of grid points to use along each parameter axis. The full
grid contains n_grid ** P points.
seed : int, optional
Random seed for reproducibility (default: 123).
method : str, optional
Evidence approximation method: 'waic', 'loo', 'laplace', or 'gmm' (default: 'waic').
grid_fraction : float, optional
Fraction of samples to use for GMM method (default: 0.1).
plot : bool, optional
Whether to generate a plot for the GMM method (default: False).
Returns
-------
dict
Dictionary containing:
- idata: ArviZ InferenceData object with posterior samples.
- method: Selected method.
- logZ: Estimated log marginal likelihood.
- Additional method-specific results (e.g., waic_result, loo_result).
Examples
--------
>>> import numpy as np
>>> # Generate synthetic data (quadratic polynomial with noise)
>>> np.random.seed(123)
>>> X = np.linspace(-2, 2, 50)
>>> true_coefs = [1, 0.5, 2] # y = 1 + 0.5x + 2x^2
>>> y = np.polyval(true_coefs[::-1], X) + np.random.normal(0, 0.5, size=50)
>>> # Fit model and estimate evidence using different methods
>>> results_waic = calculate_evidence(X, y, degree=2, method="waic")
>>> print(f"WAIC logZ: {results_waic['logZ']:.3f}")
>>> results_laplace = calculate_evidence(X, y, degree=2, method="laplace")
>>> print(f"Laplace logZ: {results_laplace['logZ']:.3f}")
>>> results_gmm = calculate_evidence(X, y, degree=2, method="gmm", plot=True)
>>> print(f"GMM logZ: {results_gmm['logZ']:.3f}")
"""
# Input validation
Xdata = np.asarray(Xdata)
ydata = np.asarray(ydata)
if Xdata.ndim not in (1, 2):
raise ValueError("Xdata must be 1D or 2D")
if ydata.ndim != 1:
raise ValueError("ydata must be 1D")
if Xdata.shape[0] != ydata.shape[0]:
raise ValueError("Xdata and ydata must have same number of samples")
if degree < 0:
raise ValueError("Degree must be non-negative")
if sigma_y <= 0 or coef_sigma <= 0:
raise ValueError("sigma_y and coef_sigma must be positive")
if method.lower() not in {"waic", "loo", "laplace", "gmm"}:
raise ValueError("Method must be 'waic', 'loo', 'laplace', or 'gmm'")
if grid_fraction <= 0 or grid_fraction > 1:
raise ValueError("grid_fraction must be in (0, 1]")
rng = np.random.default_rng(seed)
# Preprocess data
if Xdata.ndim == 1:
Xdata = Xdata[:, None]
X = np.vander(Xdata.flatten(), degree + 1, increasing=True) # Stable polynomial matrix
n_data, n_params = X.shape
# Warn about potential overfitting
if n_data < n_params:
logger.warning("Number of data points (%d) is less than number of parameters (%d)", n_data, n_params)
# PyMC model
with pm.Model() as model:
X_shared = pm.Data("X_shared", X) # Removed mutable=True
coef = pm.Normal("coef", mu=0, sigma=coef_sigma, shape=n_params)
mu = pm.math.dot(X_shared, coef)
y_obs = pm.Normal("y", mu=mu, sigma=sigma_y, observed=ydata)
try:
idata = pm.sample(
draws=n_mc // 4,
tune=1000,
chains=4,
random_seed=seed,
target_accept=0.9,
progressbar=False,
idata_kwargs={"log_likelihood": True}
)
except pm.exceptions.SamplingError as e:
logger.error("Sampling failed: %s", e)
return {"idata": None, "method": method, "logZ": np.nan}
results = {"idata": idata, "method": method}
# Extract samples
coef_da = idata.posterior["coef"]
dims_to_stack = [d for d in coef_da.dims if d != "coef_dim_0"]
coef_samples = coef_da.stack(sample=dims_to_stack).values
if coef_samples.shape[0] == n_params:
coef_samples = coef_samples.T # Ensure (n_samples, n_params)
# Evidence approximations
if method.lower() == "waic":
waic_res = az.waic(idata, pointwise=True)
results["waic_result"] = waic_res
results["logZ"] = -0.5 * waic_res.elpd_waic # Rough proxy
elif method.lower() == "loo":
loo_res = az.loo(idata, pointwise=True)
results["loo_result"] = loo_res
results["logZ"] = -0.5 * loo_res.elpd_loo # Rough proxy
elif method.lower() == "gmm":
param_grid = create_param_grid(coef_samples, n_grid=n_grid)
log_prior = -0.5 * np.sum((param_grid / coef_sigma) ** 2, axis=1)
y_pred = X @ param_grid.T
log_lik = -0.5 * np.sum(((ydata[:, None] - y_pred) / sigma_y) ** 2, axis=0)
log_numerator = log_prior + log_lik
results["logZ"] = estimate_log_evidence(
coef_samples, param_grid, log_numerator, grid_fraction=grid_fraction, plot=plot, seed=seed
)
return results
results_gmm = calculate_evidence(Xa, ya, degree=0, method="gmm", n_mc=2000, n_grid=200, grid_fraction=0.1, plot=True)
log_Ea_P0 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
INFO:/home/msn/repos/illinois-mlp/forInstructors/.venv/lib/python3.13/site-packages/pytensor/link/c/lazylinker_c.py:Compiling new CVM
INFO:/home/msn/repos/illinois-mlp/forInstructors/.venv/lib/python3.13/site-packages/pytensor/link/c/lazylinker_c.py:New version 0.31
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 500 draw iterations (4_000 + 2_000 draws total) took 0 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 500 draw iterations (4_000 + 2_000 draws total) took 0 seconds.
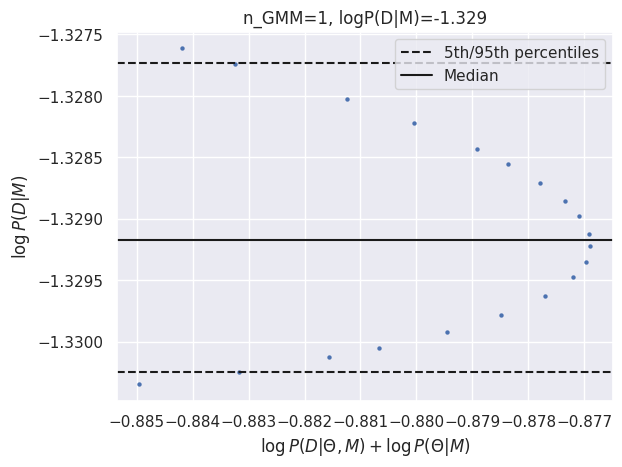
GMM logZ: -1.329
results_gmm = calculate_evidence(Xb, yb, degree=0, method="gmm", n_mc=1000, n_grid=200, grid_fraction=0.1, plot=True)
log_Eb_P0 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 250 draw iterations (4_000 + 1_000 draws total) took 0 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 250 draw iterations (4_000 + 1_000 draws total) took 0 seconds.
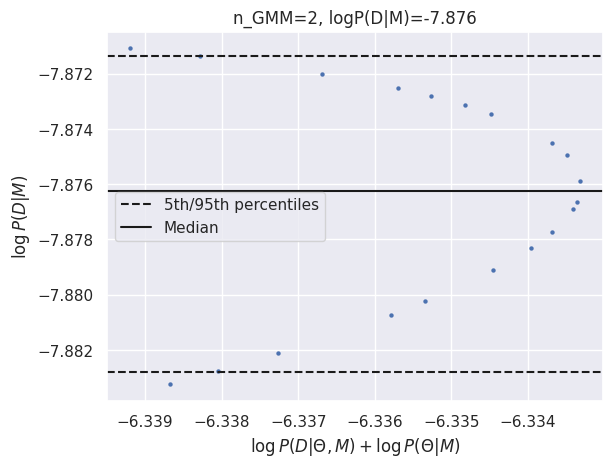
GMM logZ: -7.876
results_gmm = calculate_evidence(Xa, ya, degree=1, method="gmm", n_mc=2000, n_grid=75, grid_fraction=0.3, plot=True)
log_Ea_P1 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 500 draw iterations (4_000 + 2_000 draws total) took 0 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 500 draw iterations (4_000 + 2_000 draws total) took 0 seconds.
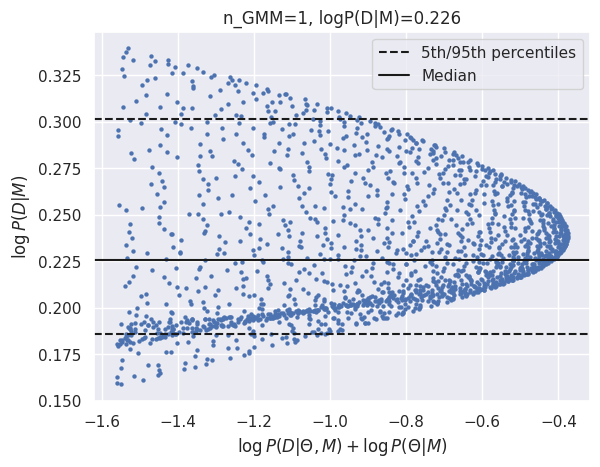
GMM logZ: 0.226
results_gmm = calculate_evidence(Xb, yb, degree=1, method="gmm", n_mc=2000, n_grid=75, grid_fraction=0.3, plot=True)
log_Eb_P1 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 500 draw iterations (4_000 + 2_000 draws total) took 0 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 500 draw iterations (4_000 + 2_000 draws total) took 0 seconds.
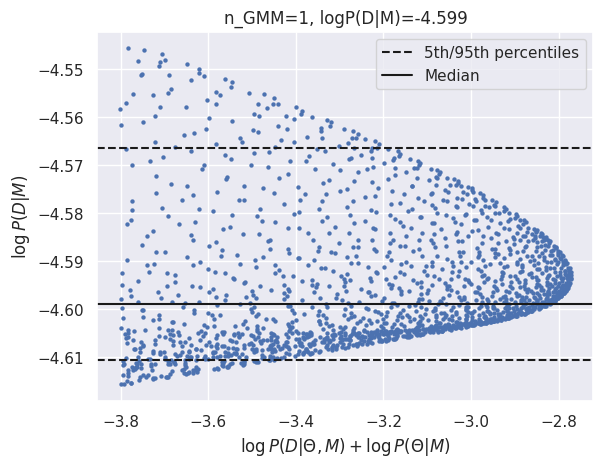
GMM logZ: -4.599
results_gmm = calculate_evidence(Xa, ya, degree=2, method="gmm", n_mc=1500, n_grid=75, grid_fraction=0.02, plot=True)
log_Ea_P2 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 375 draw iterations (4_000 + 1_500 draws total) took 1 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 375 draw iterations (4_000 + 1_500 draws total) took 1 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
INFO:pymc.stats.convergence:The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
ERROR:pymc.stats.convergence:The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
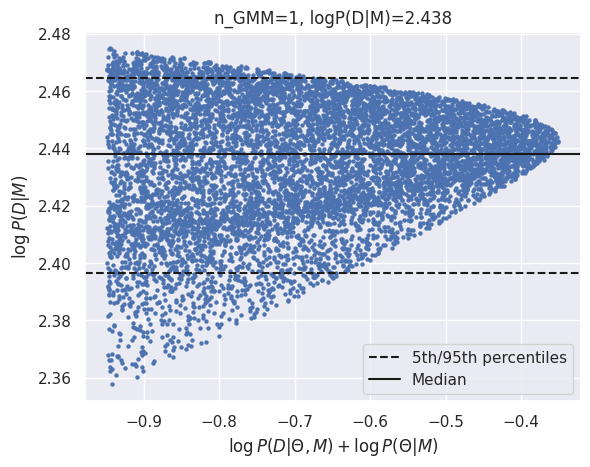
GMM logZ: 2.438
results_gmm = calculate_evidence(Xb, yb, degree=2, method="gmm", n_mc=1500, n_grid=75, grid_fraction=0.02, plot=True)
log_Eb_P2 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 375 draw iterations (4_000 + 1_500 draws total) took 1 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 375 draw iterations (4_000 + 1_500 draws total) took 1 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
INFO:pymc.stats.convergence:The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
ERROR:pymc.stats.convergence:The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
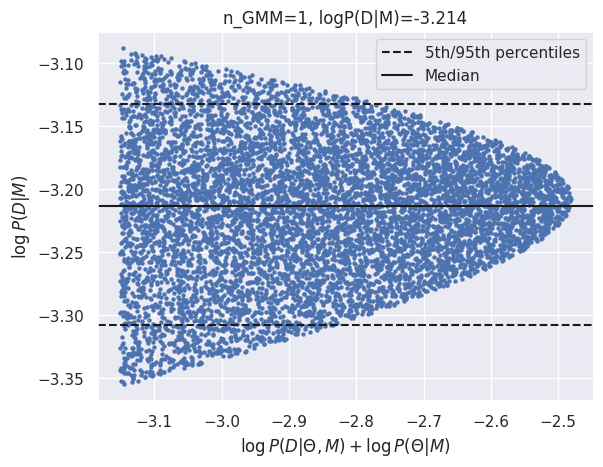
GMM logZ: -3.214
results_gmm = calculate_evidence(Xa, ya, degree=3, method="gmm", n_mc=1200, n_grid=60, grid_fraction=0.0005, plot=True)
log_Ea_P3 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 300 draw iterations (4_000 + 1_200 draws total) took 1 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 300 draw iterations (4_000 + 1_200 draws total) took 1 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
INFO:pymc.stats.convergence:The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
ERROR:pymc.stats.convergence:The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
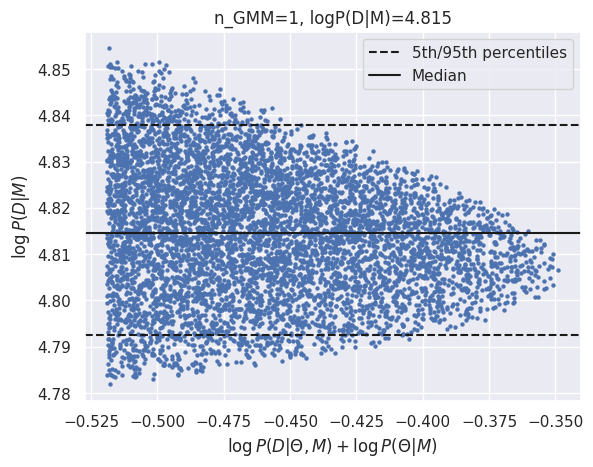
GMM logZ: 4.815
results_gmm = calculate_evidence(Xb, yb, degree=3, method="gmm", n_mc=1000, n_grid=50, grid_fraction=0.0005, plot=True)
log_Eb_P3 = results_gmm['logZ']
print(f"GMM logZ: {results_gmm['logZ']:.3f}")
Initializing NUTS using jitter+adapt_diag...
INFO:pymc.sampling.mcmc:Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
INFO:pymc.sampling.mcmc:Multiprocess sampling (4 chains in 4 jobs)
NUTS: [coef]
INFO:pymc.sampling.mcmc:NUTS: [coef]
Sampling 4 chains for 1_000 tune and 250 draw iterations (4_000 + 1_000 draws total) took 2 seconds.
INFO:pymc.sampling.mcmc:Sampling 4 chains for 1_000 tune and 250 draw iterations (4_000 + 1_000 draws total) took 2 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
INFO:pymc.stats.convergence:The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
ERROR:pymc.stats.convergence:The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
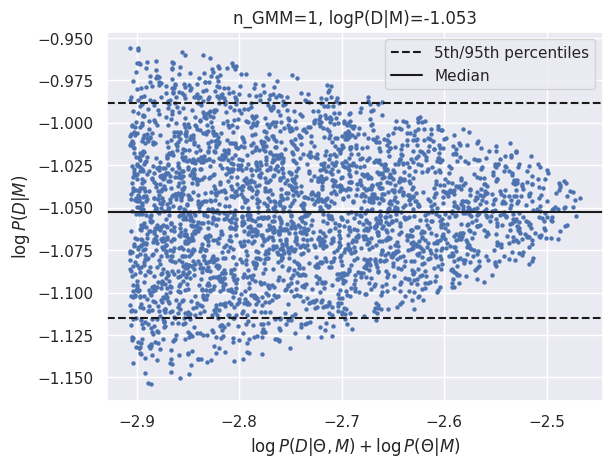
GMM logZ: -1.053
Summarize these estimated log evidence values, \(\log P(D\mid M)\), for the four models considered, P0-3:
results = pd.DataFrame({
'P0': [log_Ea_P0, log_Eb_P0], 'P1': [log_Ea_P1, log_Eb_P1],
'P2': [log_Ea_P2, log_Eb_P2], 'P3': [log_Ea_P3, log_Eb_P3]},
index=('N=15', 'N=150'))
results.round(2)
| P0 | P1 | P2 | P3 | |
|---|---|---|---|---|
| N=15 | -1.33 | 0.23 | 2.44 | 4.81 |
| N=150 | -7.88 | -4.60 | -3.21 | -1.05 |
EXERCISE: Use the table of \(\log P(D\mid M)\) values above to answer the following questions:
Which model best explains the \(N=15\) dataset?
Which model best explains the \(N=150\) dataset?
Which pairs of models have a Bayes’ factor \(> 100\), indicating “decisive evidence” favoring one model over the other?
Does “decisive evidence” that favors one model over another indicate that the favored model is correct?
Are the model comparisons based on evidence substantially different from those based on cross validation in this example?
Both the \(N=15\) and \(N=150\) datasets are best explained by the P3 model (since it has the maximum value in the first row of the table), which is probably not surprising given the modest differences of the function over this polynomial degree range.
A Bayes’ factor \(> 10\) represents strong evidence of one model over another and corresponds to a difference in \(\log P(D\mid M)\) of \(\log 10 \simeq 2.3\).
Here is a table showing which model pairs pass strong evidence test
For \(N=15\):
row = results.iloc[0].values
print(np.exp(row - row.reshape(-1, 1)) > 10)
[[False False True True]
[False False False True]
[False False False True]
[False False False False]]
And for \(N=150\):
row = results.iloc[1].values
print(np.exp(row - row.reshape(-1, 1)) > 10)
[[False True True True]
[False False False True]
[False False False False]
[False False False False]]
A Bayes’ factor \(> 100\) represents decisive evidence of one model over another and corresponds to a difference in \(\log P(D\mid M)\) of \(\log 100 \simeq 4.6\).
Here is a table showing which model pairs pass decisive evidence test
For \(N=15\):
row = results.iloc[0].values
print(np.exp(row - row.reshape(-1, 1)) > 100)
[[False False False True]
[False False False False]
[False False False False]
[False False False False]]
And for \(N=150\):
row = results.iloc[0].values
print(np.exp(row - row.reshape(-1, 1)) > 100)
[[False False False True]
[False False False False]
[False False False False]
[False False False False]]
We find that, in both cases, the P3 model is “decisively favored” over P0 and P1 as explanations for the data.
The Bayes’ factor is calculated for a pair of models, without considering the range of all possible models. A high value can either indicate that one model of the pair is particularly good or that the other model is particularly bad (or some combination of these). In this example, P0 is particularly bad. In general, the Bayes’ factor compares models relative to each other, but does not offer any absolute measure of how well either model explains the data.
These evidence-based model comparisons are broadly consistent with the earlier cross-validation comparisons, but with some differences in the details. The advantages of using evidence are clearer for the smaller dataset, where the cross validation results are difficult to interpret and priors have more influence. Ideally, you should use both methods and compare.
Appendix: Comparison with Bayesian Evidence using Emcee (alternative implementation for reference)#
import numpy as np
import emcee
from sklearn import mixture
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
def create_param_grid(samples, n_grid=50):
"""Create a parameter grid from parameter samples.
Grids are based on 1D quantiles in each parameter, so are not uniform.
Parameters
----------
samples : array
2D array with shape (N, P) containing N samples for P parameters.
n_grid : int
Number of grid points to use along each parameter axis. The full
grid contains n_grid ** P points.
Returns
-------
array
Array of shape (n_grid ** P, P) with parameters values covering the
full grid. Can be reshaped to ([P] * (P+1)) to reconstruct the
P-dimensional grid structure.
"""
samples = np.asarray(samples)
N, P = samples.shape
quantiles = np.linspace(0, 100, n_grid)
grid = [np.percentile(column, quantiles) for column in samples.T]
return np.moveaxis(np.stack(
np.meshgrid(*grid), axis=-1), (0,1), (1,0)).reshape(-1, P)
def estimate_log_evidence(samples, param_grid, log_numerator, max_components=5,
grid_fraction=0.1, plot=True, seed=123):
"""Estimate the log evidence using MCMC samples.
The evidence is estimated at each grid point using the ratio of the
log_numerator and the empirical density of samples. Only grid points with
the largest log_numerator are used for the estimate. The density is
estimated with a Gaussian mixture model using the number of components
that minimizes the spread of estimates over the selected grid points.
Parameters
----------
samples : array
2D array with shape (N, P) containing N samples for P parameters.
param_grid : array
2D array with shape (n_grid ** P, P) to specify a grid that covers
the full parameter space. Normally obtained by calling
:func:`create_param_grid`.
log_numerator : array
1D array with shape (n_grid ** P,) with the log_likelihood+log_prior
value tabulated on the input parameter grid.
max_components : int
Maximum number of Gaussian mixture model components to use in
estimating the density of samples over the parameter space.
grid_fraction : float
The fraction of grid points with the highest log_numerator to use
for estimating the log_evidence.
plot : bool
When True, draw a scatter plot of log_numerator vs log_evidence for the
requested fraction of grid points, using the best found number of
GMM components.
seed : int or None
Random seed to use for reproducible results.
Returns
-------
float
Estimate of the log evidence.
"""
samples = np.asarray(samples)
cut = np.percentile(log_numerator, 100. * (1 - grid_fraction))
use = np.where(log_numerator >= cut)[0]
use_grid = param_grid[use]
use_log_numerator = log_numerator[use]
gen = np.random.RandomState(seed=seed)
log_evidence = np.empty((max_components, len(use)))
for i in range(max_components):
fit = mixture.GaussianMixture(
n_components=i + 1, random_state=gen).fit(samples)
use_log_density = fit.score_samples(use_grid)
log_evidence[i] = use_log_numerator - use_log_density
lo, med, hi = np.percentile(log_evidence, (5, 50, 95), axis=-1)
spread = 0.5 * (hi - lo)
best = np.argmin(spread)
if plot:
plt.scatter(use_log_numerator, log_evidence[best], s=10, lw=0)
plt.xlabel('$\log P(D\mid \Theta, M) + \log P(\Theta\mid M)$')
plt.ylabel('$\log P(D\mid M)$')
plt.axhline(lo[best], ls='--', c='k')
plt.axhline(hi[best], ls='--', c='k')
plt.axhline(med[best], ls='-', c='k')
plt.title('n_GMM={}, logP(D|M)={:.3f}'.format(best + 1, med[best]))
plt.show()
return med[best]
def calculate_evidence(
Xdata,
ydata,
degree,
sigma_y=1.0,
coef_sigma=10.0,
n_mc=5000,
n_grid=100,
grid_fraction=0.1,
seed=123,
):
"""Calculate the log evidence for a polynomial regression model using MCMC.
Parameters
----------
Xdata : array
1D array of input data points.
ydata : array
1D array of output data points.
degree : int
Degree of the polynomial model.
sigma_y : float
Standard deviation of the observation noise.
coef_sigma : float
Standard deviation of the prior on polynomial coefficients.
n_mc : int
Number of MCMC samples to generate.
n_grid : int
Number of grid points per parameter for evidence estimation.
grid_fraction : float
Fraction of grid points to use for evidence estimation.
seed : int
Random seed for reproducibility.
Returns
-------
float
Estimate of the log evidence.
"""
# Ensure inputs are numpy arrays with correct shapes
Xdata = np.asarray(Xdata).reshape(-1, 1)
ydata = np.asarray(ydata).reshape(-1, 1)
print(f"Xdata shape: {Xdata.shape}, ydata shape: {ydata.shape}")
if Xdata.shape[0] != ydata.shape[0]:
raise ValueError(f"Xdata and ydata must have the same number of samples, got {Xdata.shape[0]} and {ydata.shape[0]}")
if Xdata.shape[1] != 1:
raise ValueError(f"Xdata must have exactly one feature, got {Xdata.shape[1]} features")
if Xdata.shape[0] == 0:
raise ValueError("Xdata is empty")
# Use sklearn fit to initialize MCMC chains
poly = PolynomialFeatures(degree)
X_poly = poly.fit_transform(Xdata)
print(f"Polynomial features shape: {X_poly.shape}")
polyreg = make_pipeline(PolynomialFeatures(degree), LinearRegression())
polyreg.fit(Xdata, ydata)
# Extract coefficients and intercept
intercept = polyreg.steps[1][1].intercept_
# Ensure intercept is a scalar
if isinstance(intercept, np.ndarray):
intercept = intercept.item()
intercept = np.float32(intercept)
coefs = polyreg.steps[1][1].coef_.astype(np.float32)
# Handle case where coefs is 2D
if coefs.ndim == 2:
coefs = coefs.flatten()
print(f'Raw coefs: {coefs}, shape: {coefs.shape}')
# For PolynomialFeatures(degree=1), coefs should be [0, slope]
if len(coefs) != degree + 1:
raise ValueError(f"Expected {degree + 1} coefficients for degree={degree}, got {len(coefs)}")
# Combine intercept and non-constant coefficients
coef_init = np.concatenate([np.array([intercept]), coefs[1:]])
P = len(coef_init) # Number of parameters (intercept + coefficients for x^1, ..., x^degree)
if P != degree + 1:
raise ValueError(f"Expected P={degree + 1} for degree={degree}, got P={P}")
print('Best fit coefficients:', np.round(coef_init, 3))
print(f'Number of parameters (P): {P}')
# Prepare polynomial features for model evaluation
XX = poly.fit_transform(Xdata)
def log_joint(coef, x_data=XX, y_data=ydata):
"""Compute the log joint probability (log likelihood + log prior)."""
if coef.shape != (P,):
coef = coef.reshape(P)
y_true = np.dot(x_data, coef)
log_likelihood = -0.5 * np.sum((y_data.flatten() - y_true) ** 2 / sigma_y ** 2)
log_likelihood -= len(y_data) * np.log(sigma_y * np.sqrt(2 * np.pi))
log_prior = -0.5 * np.sum(coef ** 2 / coef_sigma ** 2)
log_prior -= P * np.log(coef_sigma * np.sqrt(2 * np.pi))
return log_likelihood + log_prior
# Define the log probability function for emcee
def log_prob(coef):
return log_joint(coef)
# Set up the MCMC sampler with emcee
np.random.seed(seed)
n_walkers = max(2 * P, 32)
print(f'Number of walkers: {n_walkers}')
initial_positions = coef_init + np.random.normal(0, 0.1, (n_walkers, P))
print(f'Initial positions shape: {initial_positions.shape}')
# Verify initial positions
if initial_positions.shape != (n_walkers, P):
raise ValueError(f"Initial positions shape {initial_positions.shape} does not match (n_walkers={n_walkers}, P={P})")
sampler = emcee.EnsembleSampler(n_walkers, P, log_prob)
# Run burn-in
num_burnin_steps = 2000
try:
pos, prob, state = sampler.run_mcmc(initial_positions, num_burnin_steps, progress=False)
except ValueError as e:
print(f"Error during burn-in: {e}")
raise
sampler.reset()
# Run production MCMC
sampler.run_mcmc(pos, n_mc, progress=False)
coef_samples = sampler.get_chain(flat=True)
# Build a parameter grid for estimating the evidence
coef_grid = create_param_grid(coef_samples, n_grid=n_grid)
# Evaluate log(likelihood) + log(prior) on the parameter grid
log_numerator_grid = np.array([log_joint(coef) for coef in coef_grid])
return estimate_log_evidence(
coef_samples,
coef_grid,
log_numerator_grid,
grid_fraction=grid_fraction,
seed=seed
)
#log_Ea_P0 = calculate_evidence(Xa, ya, 0, n_mc=2000, n_grid=200, grid_fraction=0.5)
#log_Eb_P0 = calculate_evidence(Xb, yb, 0, n_mc=2000, n_grid=200, grid_fraction=0.5)
#log_Ea_P1 = calculate_evidence(Xa, ya, 1, n_mc=2000, n_grid=75, grid_fraction=0.3)
#log_Eb_P1 = calculate_evidence(Xb, yb, 1, n_mc=2000, n_grid=75, grid_fraction=0.3)
#log_Ea_P2 = calculate_evidence(Xa, ya, 2, n_mc=1500, n_grid=75, grid_fraction=0.02)
#log_Eb_P2 = calculate_evidence(Xb, yb, 2, n_mc=1500, n_grid=75, grid_fraction=0.02)
#log_Ea_P3 = calculate_evidence(Xa, ya, 3, n_mc=700, n_grid=60, grid_fraction=0.0005)
#log_Eb_P3 = calculate_evidence(Xb, yb, 3, n_mc=700, n_grid=60, grid_fraction=0.0005)
Acknowledgments#
Initial version: Mark Neubauer
© Copyright 2026