Solving the Time Dependent Schrodinger Equation with Physics-Informed Deep Learning#
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import matplotlib as mpl
from matplotlib.lines import Line2D
import matplotlib.image as img
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
from ipywidgets import interact
import ipywidgets as widgets
import warnings
warnings.filterwarnings('ignore')
Helper Functions#
def viz_colour_rgb(c):
labels = ['r','g','b','','col']
w = [1,1,1]
cb = np.zeros((1,5,3))
cb[0,0,0] = c[0]
cb[0,1,1] = c[1]
cb[0,2,2] = c[2]
cb[0,3,:] = w
cb[0,4,:] = c
fig = plt.figure(figsize = (5,10))
ax = fig.add_axes([0,0, 1, 1]) # span the whole figure
ax.set_xticks(np.arange(len(labels)))
ax.set_xticklabels(labels)
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=0, ha="left",
rotation_mode="anchor")
ax.tick_params(left = False, right = False , labelleft = False ,
labelbottom = True, bottom = False)
ax.imshow(cb)
plt.show()
print(f"r = {float(c[0]):.2}, g = {float(c[1]):.2}, b = {float(c[2]):.2}")
def viz_colour_predicted_rgb(t,p):
print("Input RGB:")
viz_colour_rgb(t)
print("\nOutput Prediction RGB:")
viz_colour_rgb(p)
print("##############################")
rgb_scale = 1.0
cmyk_scale = 1.0
def rgb_to_cmyk(col):
r,g,b = col
if (r == 0) and (g == 0) and (b == 0):
# black
return 0, 0, 0, cmyk_scale
# rgb [0,1] -> cmy [0,1]
c = 1 - r
m = 1 - g
y = 1 - b
# extract out k [0,1]
min_cmy = min(c, m, y)
c = (c - min_cmy)
m = (m - min_cmy)
y = (y - min_cmy)
k = min_cmy
# rescale to the range [0,cmyk_scale]
return c*cmyk_scale, m*cmyk_scale, y*cmyk_scale, k*cmyk_scale
def cmyk_to_rgb(col):
"""
"""
c,m,y,k = col
r = max(1.0-(c+k),0.0)
g = max(1.0-(m+k),0.0)
b = max(1.0-(y+k),0.0)
return r,g,b
def viz_colour_cmyk(c):
labels = ['c','m','y','k','','col']
c = np.asarray(c)
cyan = np.asarray([0,1.0,1.0])
magenta = np.asarray([1.0,0.0,1.0])
yellow = np.asarray([1.0,1.0,0.0])
w = np.asarray([1,1,1])
cyan = np.asarray([1.0,0,0,0])
magenta = np.asarray([0,1,0,0])
yellow = np.asarray([0,0,1,0])
w = np.asarray([1,1,1])
rgb_c = cmyk_to_rgb(c)
cb = np.zeros((1,6,3))
cb[0,0,:] = cmyk_to_rgb(c[0] * cyan)
cb[0,1,:] = cmyk_to_rgb(c[1] * magenta)
cb[0,2,:] = cmyk_to_rgb(c[2] * yellow)
cb[0,3,:] = (1 - c[3]) * w
cb[0,4,:] = w
cb[0,5,:] = rgb_c
fig = plt.figure(figsize = (5,10))
ax = fig.add_axes([0,0, 1, 1]) # span the whole figure
#ax.set_axis_off()
ax.set_xticks(np.arange(len(labels)))
ax.set_xticklabels(labels)
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=0, ha="left",
rotation_mode="anchor")
ax.tick_params(left = False, right = False , labelleft = False ,
labelbottom = True, bottom = False)
ax.imshow(cb)
plt.show()
print(f"c = {float(c[0]):.2}, m = {float(c[1]):.2}, y = {float(c[2]):.2}, k = {float(c[3]):.2}")
def viz_colour_predicted_cmyk(t,p):
print("Input RGB:")
viz_colour_rgb(t)
print("\nOutput Prediction:")
viz_colour_cmyk(p)
print("##############################")
class ColourDataset(Dataset):
def __init__(self, input_data, output_data, transform=None):
self.input_data = input_data
self.output_data = output_data
self.transform = transform
def __len__(self):
return len(self.input_data)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
sample = [self.input_data[idx], self.output_data[idx]]
return sample
debug = False
def get_plots_norm_colorbar(y_true,y_pred, n_x, n_t, x_dom, t_dom, plot_fname):
labels = ["Predicted", "True", "Abs Err"]
u,v,dens = get_density(y_true.detach().cpu().numpy())
u_pred, v_pred, dens_pred = get_density(y_pred.detach().cpu().numpy())
plot_name = 'TD SE Results' #remove 'network_checkpoint_'
fig = plt.figure(figsize=(7,8),dpi=100)
mse_u = 0.0
mse_v = 0.0
show_cb = False
cmap = plt.get_cmap('viridis')
x_min = 0
x_max = 0
t_min = 0
t_max = 0
u_max = -99.
u_min = 99.
v_max = -99.
v_min = 99.
d_max = -99.
d_min = 99.
u_max = np.max((np.max(u),np.max(u_pred)))
u_min = np.min((np.min(u),np.min(u_pred)))
v_max = np.max((np.max(v),np.max(v_pred)))
v_min = np.min((np.min(v),np.min(v_pred)))
d_max = np.max((np.max(dens),np.max(dens_pred)))
d_min = np.min((np.min(dens),np.min(dens_pred)))
extent = [x_dom[0] , x_dom[1], t_dom[0] ,t_dom[1]]
u_plot = np.zeros((n_x,n_t))
v_plot = np.zeros_like((n_x,n_t))
d_plot = np.zeros_like((n_x,n_t))
reshape_to_grid = lambda x: np.reshape(x, (n_x, n_t))
for i in np.arange(3):
if i==0:
u_plot = reshape_to_grid(u_pred)
v_plot = reshape_to_grid(v_pred)
d_plot = reshape_to_grid(dens_pred)
show_cb = False
if i==1:
u_plot = reshape_to_grid(u)
v_plot = reshape_to_grid(v)
d_plot = reshape_to_grid(dens)
if i == 2:
u_plot = np.abs(reshape_to_grid(u - u_pred))
v_plot = np.abs(reshape_to_grid(v - v_pred))
d_plot = np.abs(reshape_to_grid(dens_pred - dens))
show_cb = True
ax1 = fig.add_subplot(3,3,i+1)
ims = ax1.imshow(u_plot, extent=extent,vmin=u_min, vmax=u_max)
ax1.set_title(fr"{labels[i]} Re($\psi$)")
ax1.set_xlabel(r'$x$')
ax1.set_ylabel(r'$t$')
if show_cb:
divider = make_axes_locatable(ax1)
cax = divider.append_axes("right", size="5%", pad=0.05)
norm = mpl.colors.Normalize(vmin=u_min, vmax=u_max)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
fig.colorbar(sm, cax=cax)
ax1 = fig.add_subplot(3,3,i+4)
ax1.set_title(fr"{labels[i]} Im($\psi$)")
ims = ax1.imshow(v_plot, extent=extent,vmin=v_min, vmax=v_max)
ax1.set_xlabel(r'$x$')
ax1.set_ylabel(r'$t$')
if show_cb:
divider = make_axes_locatable(ax1)
cax = divider.append_axes("right", size="5%", pad=0.05)
norm = mpl.colors.Normalize(vmin=v_min, vmax=v_max)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
fig.colorbar(sm, cax=cax)
ax1 = fig.add_subplot(3,3,i+7)
ax1.set_title(fr"{labels[i]} $|\psi|^2$")
ims = ax1.imshow(d_plot, extent=extent,vmin=d_min, vmax=d_max)
ax1.set_xlabel(r'$x$')
ax1.set_ylabel(r'$t$')
if show_cb:
divider = make_axes_locatable(ax1)
cax = divider.append_axes("right", size="5%", pad=0.05)
norm = mpl.colors.Normalize(vmin=d_min, vmax=d_max)
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
fig.colorbar(sm, cax=cax)
if i==2:
mse_u = np.mean(u_plot**2)
mse_v = np.mean(v_plot**2)
print(f"{i} finished")
plot_title = plot_name
plt.suptitle(fr"{plot_title}",y=0.92)
plt.savefig(f'./tmp_data/{plot_fname}')
plt.show()
print(f"mse: u: {mse_u}, v:{mse_v}")
return mse_u,mse_v
def get_density(y_pred):
# Helper function to split data into real, imag, density
u = y_pred[:,0]
v = y_pred[:,1]
dens = u**2 + v**2
return u,v,dens
def get_waveforms(analytical_solution_function):
L = float(np.pi)
omega = 1
delta_T = 0.1
delta_X = 0.1
x_dom = [-L,L]
t_dom = [0, 2*L]
x = np.arange(x_dom[0], x_dom[1], delta_X).astype(float)
t = np.arange(t_dom[0], t_dom[1], delta_T).astype(float)
X, T = np.meshgrid(x, t)
psi_val = analytical_solution_function(X,T,omega)
u = np.real(psi_val)
v = np.imag(psi_val)
dens = u**2 + v**2
max_d = np.max(dens)+0.02
for t_step in range(len(t)):
curr_u = u[t_step,:]
curr_v = v[t_step,:]
curr_d = dens[t_step,:]
fig, ax = plt.subplots()
plt.ylim(0.0,max_d)
ax.plot(x, curr_d)
ax.set(xlabel='x (au)', ylabel=r'Probability Density $|\psi(x)|^2$',
title=fr'$|\psi(x)|^2$ at t={t[t_step]:.2f} au')
ax.grid()
fig.savefig(f"tmp_data/waveform/t_{str(t_step).zfill(2)}.png")
plt.show()
return None
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#print(device)
torch.set_default_dtype(torch.float32)
#torch.set_default_device('cpu')
device = torch.device(
"cuda:0" if torch.cuda.is_available()
else "mps" if torch.backends.mps.is_available()
else "cpu"
)
print("CUDA:", torch.cuda.is_available())
print("MPS:", torch.backends.mps.is_available())
print("Selected device:", device)
print("Default dtype:", torch.get_default_dtype())
CUDA: False
MPS: True
Selected device: mps
Default dtype: torch.float32
Brief Overview#
The Time-Independent Schrödinger Equation is a fundamental equation in quantum mechanics that describes how the quantum state of a physical system changes in space, but not in time. It is derived from the more general Time-Dependent Schrödinger Equation (TDSE) under the assumption that the system is in a steady state, meaning the potential energy within the system does not change with time. The TISE is crucial for understanding the behavior of particles in potential wells, quantum tunneling, and the quantization of energy levels in atoms and molecules.
Mathematical Formulation#
The Time-Independent Schrödinger Equation can be introduced starting from the fundamental relationship involving the Hamiltonian operator \( \hat{H} \) acting on the wave function \( \psi \), equating it to the energy \( E \) of the system times the wave function. This is expressed as:
The Hamiltonian operator \( \hat{H} \) represents the total energy of the system and is composed of the kinetic energy (\( T \)) and potential energy (\( V \)) operators:
where the kinetic energy operator \( \hat{T} \) is given by:
and \( \hat{V} \) represents the potential energy operator, which in position space is simply multiplication by the potential energy function \( V(\mathbf{r}) \):
Substituting the expressions for \( \hat{T} \) and \( \hat{V} \) into the Hamiltonian, we obtain the Time-Independent Schrödinger Equation in position space:
Here:
\( \hbar \) is the reduced Planck’s constant (\( \hbar = \frac{h}{2\pi} \)),
\( m \) is the mass of the particle,
\( \nabla^2 \) is the Laplacian operator, indicating the second spatial derivatives,
\( \psi(\mathbf{r}) \) is the wave function of the particle, a complex function that provides information about the probability amplitude of the particle’s position,
\( V(\mathbf{r}) \) is the potential energy as a function of position,
\( E \) is the total energy of the system, which is a constant for time-independent systems.
Physical Interpretation#
The Time-Independent Schrödinger Equation is an eigenvalue equation where the eigenvalues \( E \) correspond to the energy levels of the system, and the eigenfunctions \( \psi(\mathbf{r}) \) represent the stationary states. The probability density of finding the particle at a given position \( \mathbf{r} \) is given by the square modulus of the wave function, \( |\psi(\mathbf{r})|^2 \).
Infinite Square Well#
The infinite square well (or particle in a box) is a fundamental quantum mechanical system that provides profound insights into the quantization of energy. In this model, a particle is confined to a one-dimensional box with infinitely high walls, leading to discrete energy levels. The potential \(V(x)\) can be described as:
where \(L\) is the width of the well. For the region inside the well (\(0 \leq x \leq L\)), the TISE simplifies to:
Analytic Solution#
The boundary conditions dictate that \(\psi(x) = 0\) at \(x = 0\) and \(x = L\), leading to quantized energy levels. The solutions to the TISE in this case are sinusoidal functions inside the well:
The corresponding energy levels are given by:
Let us implement the potential and analytical solution:
# Exercise
def V_infinite_well(x, params):
L = params
return np.zeros_like(x)
def analytical_eigenvalues_infinite_well(n, params):
n = n + 1 # avoiding trivial solution
L = params
E = (n * np.pi / L)**2/2
return E
def analytical_eigenfunctions_infinite_well(x, n, params):
n = n + 1 # avoiding trivial solution
L = params
psi = np.sqrt(2 / L) * np.sin(n * np.pi * x / L)
return normalize_wavefunction(psi, x)
Setting up TISE Solver#
We take a short detour to study a simple numerical method to get the derivates. It is called the Finite Difference Method.
We know that first derivative of a function \(f(x)\) at a point \(x\) represents the rate at which \(f(x)\) changes with respect to \(x\). The first derivative is defined as the limit of the average rate of change of the function as the interval over which the change is measured approaches zero. Mathematically, this is expressed as:
where \(h\) is the difference between the neighboring point \(x+h\) and the point \(x\), and \(f(x+h) - f(x)\) represents the change in the function’s value over that interval. The expression \(\frac{f(x+h) - f(x)}{h}\) calculates the average rate of change of \(f(x)\) over the interval from \(x\) to \(x+h\).
The approximation of the first derivative works based on the principle of this definition. In practice, we cannot take the limit as \(h\) goes to zero because that would require infinitesimally small steps, which are not possible to handle with numerical computations. Instead, we choose a small but finite value of \(h\), which allows us to approximate the instantaneous rate of change (the derivative) by calculating the slope of the secant line that passes through the points \((x, f(x))\) and \((x+h, f(x+h))\).
So, we have
for a finite \(h\). This formula gives a first-order approximation of the derivative.
Let’s implement this in python for an arbitrary function f at grid points x_grid
# Exercise: Get the first derivative numerically
def approximate_first_derivative(f, x_grid):
dfdx = np.zeros_like(x_grid)
# Compute the spacing based on the input grid
# Assuming uniform spacing
h = x_grid[1] - x_grid[0]
# Forward difference for all points except the last
dfdx[:-1] = (f(x_grid[1:]) - f(x_grid[:-1])) / h
# This is provided to make sure that the last point is not left out.
# Since we don't have a forward difference for the last point, we'll use a backward difference.
# It is similar to the forward difference, but we use the previous point instead of the next point.
dfdx[-1] = (f(x_grid[-1]) - f(x_grid[-2])) / h
return dfdx
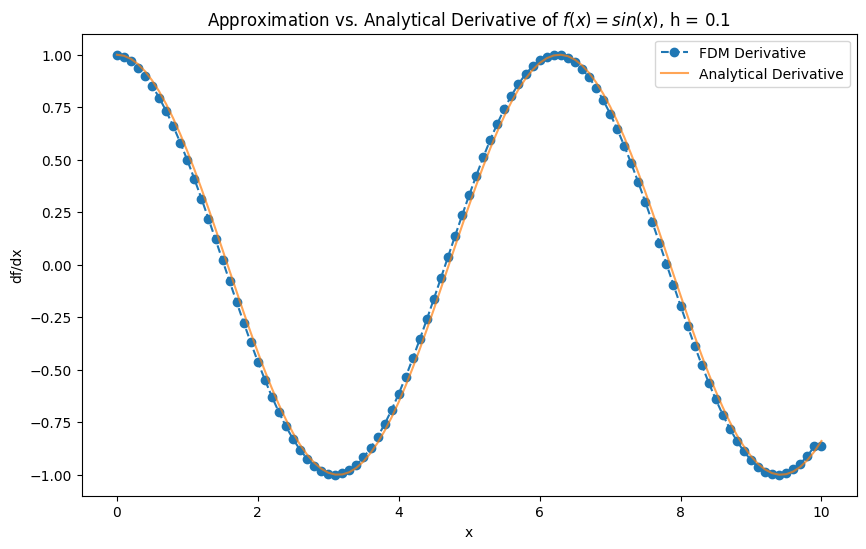
def test_derivative(k):
x_min = 0
x_max = 10
N = (x_max - x_min)/10**k + 1
x = np.linspace(0, 10, int(N))
f = np.sin
dfdx_approx = approximate_first_derivative(f, x)
dfdx_exact = np.cos(x)
plt.figure(figsize=(10, 6))
plt.plot(x, dfdx_approx, label='FDM Derivative', marker='o', linestyle='--')
plt.plot(x, dfdx_exact, label='Analytical Derivative', alpha=0.7)
plt.xlabel('x')
plt.ylabel('df/dx')
plt.title(f'Approximation vs. Analytical Derivative of $f(x) = sin(x)$, h = {x[1]-x[0]}')
plt.legend()
plt.show()
test_derivative(-1)
To approximate the second derivative, we start from the basic first derivative approximations and extend them. The second derivative at a point \(x_i\) can be derived by applying the first derivative approximation twice, leading to:
Exercise: Use the forward difference formula for \(f'(x_{i+1})\) and \(f'(x_i)\) and simplify the above equation to get:
This gives us a second-order accurate approximation of the second derivative.
Notice that x grid is a vector of length \(N+1\). We can represent this as a matrix multiplication
where f(x) is the vector of legth \(N+1\), and FD2 is a matrix of shape \(N+1, N+1\) with diagonal elements corresponding to the terms in the finite difference equation you derived above. Let’s implement this in code:
# Exercise
def get_fd2_matrix(x_grid, fix_boundary=False):
# Define the matrix
N = len(x_grid)
h = x_grid[1] - x_grid[0]
# Main diagonal values (central differences for the second derivative)
main_diagonal = -2.0 * np.ones(N) / h**2
# Off diagonal values (one step off the main diagonal)
off_diagonal = 1.0 * np.ones(N - 1) / h**2
# Assemble the tridiagonal matrix
fd_matrix = np.diag(main_diagonal) + np.diag(off_diagonal, 1) + np.diag(off_diagonal, -1)
# These are for numerical stability. We use higher order terms at the boundaries.
if fix_boundary:
if N > 4:
fd_matrix[0, :4] = [2, -5, 4, -1] / h**2
fd_matrix[-1, -4:] = [-1, 4, -5, 2] / h**2
else:
raise ValueError("The grid is too small to use higher order terms.")
return fd_matrix
This is what the matrix looks like:
mat = get_fd2_matrix(np.arange(0,5,1)/1)
print(mat)
[[-2. 1. 0. 0. 0.]
[ 1. -2. 1. 0. 0.]
[ 0. 1. -2. 1. 0.]
[ 0. 0. 1. -2. 1.]
[ 0. 0. 0. 1. -2.]]
Do you notice the [1, -2, 1] pattern from our derivation?
Now we use this matrix on our test problem sin(x)
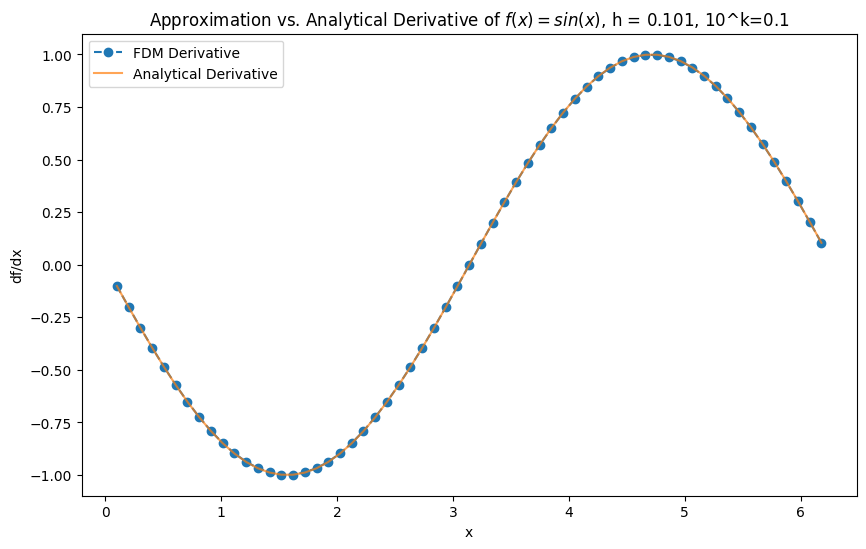
def test_second_derivative(k, show_boundary=False, fix_boundary=False):
x_min = 0
x_max = 6.28
N = (x_max - x_min)/10**k + 1
x = np.linspace(x_min, x_max, int(N))
f = np.sin(x)
mask = np.arange(len(x))
if not show_boundary:
mask = mask[1:-1]
fd_matrix = get_fd2_matrix(x, fix_boundary=fix_boundary)
df2dx2_approx = fd_matrix @ f
dfdx_exact = -np.sin(x)
# print(f"{k=}, {show_boundary=}")
plt.figure(figsize=(10, 6))
plt.plot(x[mask], df2dx2_approx[mask], label='FDM Derivative', marker='o', linestyle='--')
plt.plot(x[mask], dfdx_exact[mask], label='Analytical Derivative', alpha=0.7)
plt.xlabel('x')
plt.ylabel('df/dx')
plt.title(f'Approximation vs. Analytical Derivative of $f(x) = sin(x)$, h = {x[2]-x[1]:.3}, 10^k={10**k}')
plt.legend()
plt.show()
test_second_derivative(-1)
The second derivative in the kinetic energy term can be approximated using the central difference formula:
Substituting this into the TISE, we get a discrete version:
This leads to a system of linear equations that can be represented in matrix form as \(H\vec{\psi} = E\vec{\psi}\), where \(H\) is a tridiagonal matrix with the diagonal elements given by \(\left(\frac{1}{h^2} + V(x_i)\right)\) and the off-diagonal elements by \(-\frac{1}{2h^2}\).
Now this eigenvalue problem can be solved by matrix inversion methods that you learnt about in your Linear Algebra course. We will use the built-in np.linalg.eigh function to get the eigenvalues and eigenvectors. The function takes a potential function V and its params.
# Utility: Normalize wavefunction
def normalize_wavefunction(psi, x):
density = np.conj(psi) * psi
integral_density = np.trapz(density, x)
return psi/np.sqrt(integral_density)
# Exercise: Use the functions we defined to set up a TISE solver
def solve_tise(V, params, x_min, x_max, N, state_n=0):
# Discretize the spatial domain
x = np.linspace(x_min, x_max, N)
# Evaluate the potential energy
V_x = V(x, params)
# Assemble the Hamiltonian matrix
T_mat = get_fd2_matrix(x)
V_mat = np.diag(V_x)
H_mat = -0.5 * T_mat + V_mat
# Solve the eigenvalue problem
E, psi = np.linalg.eigh(H_mat)
E = E[state_n]
psi = psi[:, state_n]
# Normalize the wavefunction
psi = normalize_wavefunction(psi, x)
return x, E, psi
# Utility: Plotting the wavefunction
def wavefunction_plotter(V, params, x_min, x_max, N, state_n=0, true_wavefunction_fn=None, true_energy_fn=None, sys_name="System"):
x, E, psi = solve_tise(V, params, x_min, x_max, N, state_n)
if true_wavefunction_fn is not None and true_energy_fn is not None:
true_E = true_energy_fn(state_n, params)
true_wfs = true_wavefunction_fn(x, state_n, params)
# Normalize the wavefunction
true_density = np.conj(true_wfs) * true_wfs
integral_density = np.trapz(true_density, x)
true_wfs = true_wfs/ np.sqrt(integral_density)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(7.5, 9))
ax1.plot(x, psi, label=f'E_{state_n} = {E:.2f}')
if true_wavefunction_fn is not None and true_energy_fn is not None:
ax1.plot(x, true_wfs, label=f'True E_{state_n} = {true_E:.2f}', linestyle='--')
ax1_right = ax1.twinx()
ax1_right.plot(x, V(x, params), label='V(x)', color='black')
ax1_right.set_ylabel('V(x)')
ax1.set_xlabel('x')
ax1.set_ylabel(r'$\psi(x)$')
ax1.set_title(f'Wavefunction for {sys_name}, state {state_n}')
ax1.legend(loc='upper left')
ax1_right.legend(loc='upper right')
density = np.conj(psi) * psi
ax2.plot(x, density, label=r'Density |$\psi$|^2')
if true_wavefunction_fn is not None and true_energy_fn is not None:
ax2.plot(x, true_density, label=r'True Density |$\psi$|^2', linestyle='--')
ax2_right = ax2.twinx()
ax2_right.plot(x, V(x, params), color='black')
ax2_right.set_ylabel('V(x)')
ax2.set_xlabel('x')
ax2.set_ylabel(r'|$\psi(x)$|^2')
ax2.set_title(f'Density for {sys_name}, state {state_n}')
ax2.legend(loc='upper left')
ax2_right.legend(loc='upper right')
plt.tight_layout()
plt.show()
Now let us solve it with our numerical solver:
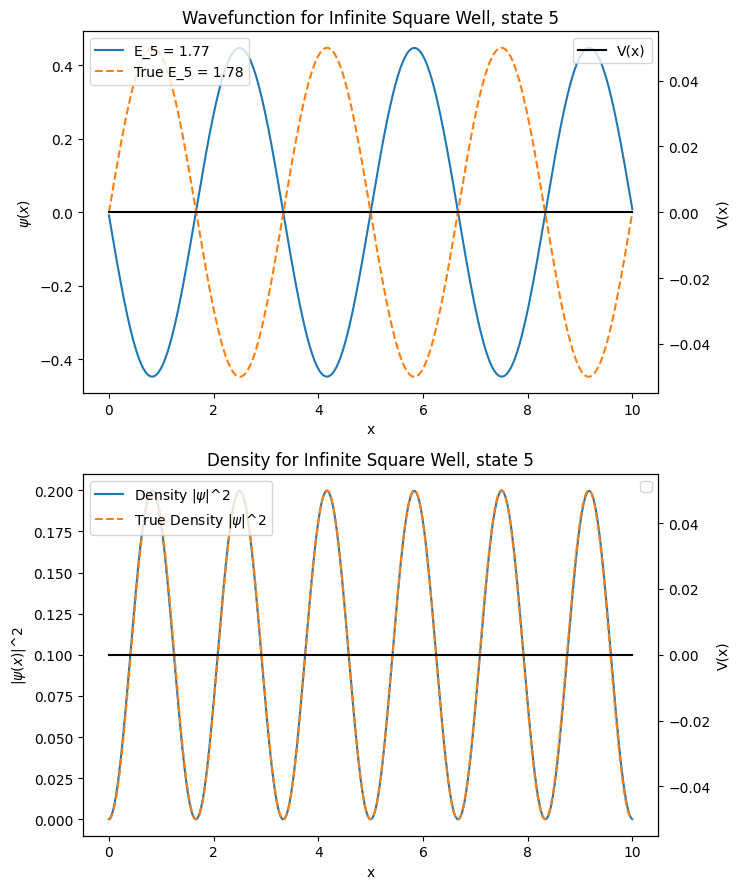
L = 10
x_min = 0
x_max = L
N = 1001
V = V_infinite_well
params = L
n_state = 5
true_wavefunction_fn=analytical_eigenfunctions_infinite_well
true_energy_fn=analytical_eigenvalues_infinite_well
sys_name = "Infinite Square Well"
wavefunction_plotter(V, params, x_min, x_max, N, n_state, true_wavefunction_fn=true_wavefunction_fn, true_energy_fn=true_energy_fn, sys_name=sys_name)
state_n_slider = widgets.IntSlider( value=0, min=0, max=10, step=1, description='state_n:', continuous_update=False)
def interactive_wavefunction_plotter(state_n):
wavefunction_plotter(V, params, x_min, x_max, N, state_n, true_wavefunction_fn, true_energy_fn, sys_name)
interactive_plot = widgets.interactive(interactive_wavefunction_plotter, state_n=state_n_slider)
display(interactive_plot)
Quantum Harmonic Oscillator (Time Independent)#
The quantum harmonic oscillator models a particle moving under a restoring force proportional to its displacement from a equilibrium position, akin to a mass on a spring. The potential energy \(V(x)\) of the QHO is given by:
where \(m\) is the mass of the particle, \(\omega\) is the angular frequency of the oscillator, and \(x\) is the displacement from equilibrium. In quantum mechanics, the TISE for the harmonic oscillator becomes:
Analytic Solution#
The solutions to the quantum harmonic oscillator are Hermite polynomials multiplied by a Gaussian exponential. The energy eigenvalues are given by:
The analytical solution \(\psi(x,t) \in \mathbb{C}\) is $\( \Large \psi_0(x) = \sqrt[4]{\frac{\omega}{\pi}}e^{\left(-\frac{\omega x^2}{2}\right)} \)$
and
where \(Her_n\) are the Hermite polynomials of degree \(n\).
Let us implement the potential:
# Exercise
def V_harmonic_oscillator(x, params):
omega = params
v = 0.5 * omega**2 * x**2
return v
To implement the analytical solution, we need to first implement Hermite polynomials. We will use the recursive definition:
\(H_0(x) = 1\)
\(H_1(x) = 2x\)
\(H_{n+1}(x) = 2xH_n(x) - 2nH_{n-1}(x)\) for \(n \geq 1\)
Let’s implement this recursive definition:
# Exercise: Use the above recursive relation to calculate the Hermite polynomials
def hermite_polynomial(n, x):
if n == 0:
return np.ones_like(x)
elif n == 1:
return 2 * x
else:
return 2 * x * hermite_polynomial(n - 1, x) - 2 * (n - 1) * hermite_polynomial(n - 2, x)
# Exercise
def analytical_eigenvalues_harmonic_oscillator(n, params):
omega = params
E = (n + 0.5) * omega
return E
def analytical_eigenfunctions_harmonic_oscillator(x, n, params):
omega = params
psi_0 = (omega/np.pi)**0.25 * np.exp(-0.5 * omega * x**2)
if n > 0:
prefactor = 1 / np.sqrt(2**n * factorial(n))
hermite_polynomial_n = hermite_polynomial(n, np.sqrt(omega) * x)
psi = prefactor * hermite_polynomial_n * np.exp(-0.5 * omega * x**2)
return normalize_wavefunction(psi, x)
else:
return normalize_wavefunction(psi_0, x)
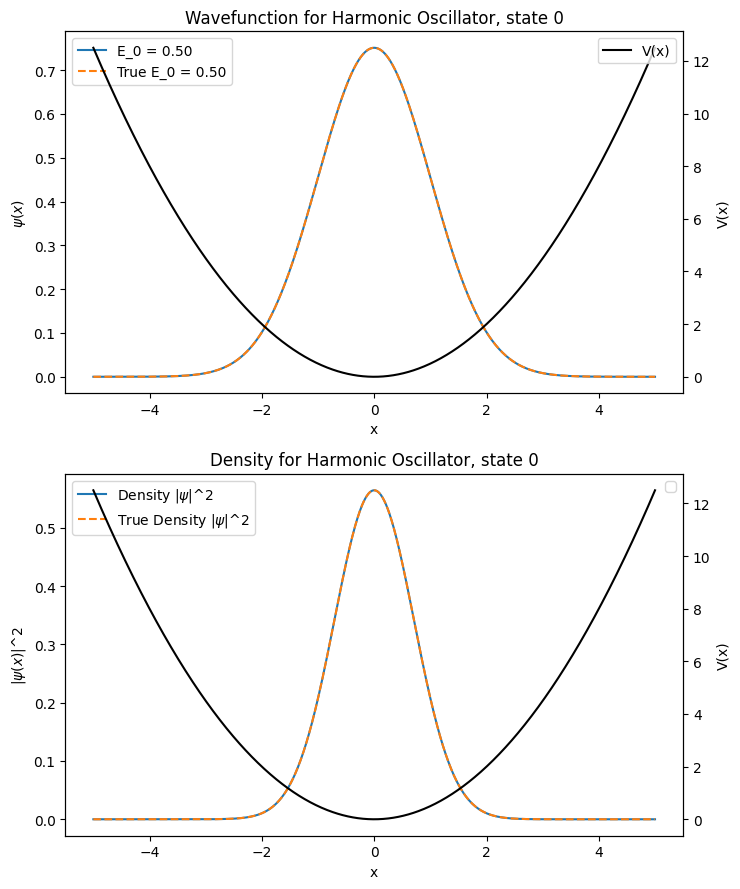
wavefunction_plotter(V_harmonic_oscillator, 1, -5, 5, 1001, 0, analytical_eigenfunctions_harmonic_oscillator, analytical_eigenvalues_harmonic_oscillator, "Harmonic Oscillator")
Quantum Harmonic Oscillator (Time Dependent)#
Next, we want to solve a Quantum Harmonic Oscillator consisting of a superposition of two states. Note: We will use atomic units unless specified: \(\hbar=m=e=1\).
The governing equation is time-dependent Schrödinger equation
for a quantum harmonic oscillator consisting of the superposition of two eigenstates \(m,n\). In the one-dimensional case, the Hamiltonian is
The analytical solution \(\psi(x,t) \in \mathbb{C}\) is
For higher states,
where \(Her_n(\sqrt{\omega}x)\) is the \(n^{\rm th}\) Hermite polynomial, and phase \(\exp\left(-i E_n t\right)\) where \(E_n = (n+\frac{1}{2})\omega\)
The superposition is defined as
Base case: \(\psi_{0,1}(x,t)\)#
Let’s derive the analytical solution for \(\psi_{0,1}(x,t)\).
The \(n^{\rm th}\) Physicist’s Hermite Polynomial is defined as:
Now that we have our analytical solution, let’s write some code to compute it for arbitrary values of \(x,t,\omega\)
def get_analytical_solution_base(X,T,omega):
# Analytical solution for first two states. X,T are numpy arrays, omega is a float.
# Hint: Avoid using for loops, use numpy functions to calculate the wavefunction.
#Solution:
phi_0 = (omega / np.pi) ** (1. / 4.) * np.exp(-X * omega * X / 2.0)
phi_1 = phi_0 * np.sqrt(omega / 2.) * 2.0 * X
psi = np.sqrt(1. / 2.) * (np.exp(-1j * omega/2 * T) * phi_0 + np.exp(-1j* 3/2 * omega * T) * phi_1)
return psi
Let’s define the domain for our problem:
We will restrict our domain to \(\mathbf{x} \in [-\pi,\pi], t \in [0,T]\), with fixed boundary conditions \(x_0, x_b = 0\) in this notebook.
After you go through the notebook, feel free to play with the code for other domains. Let’s create some data using the function we just wrote.
def get_data_set(x_dom, t_dom, delta_X, delta_T, omega, analytical_solution_fun):
# Helper function to generate datasets from analytical solutions.
x = np.arange(x_dom[0], x_dom[1], delta_X).astype(float)
t = np.arange(t_dom[0], t_dom[1], delta_T).astype(float)
X, T = np.meshgrid(x, t)
X = np.expand_dims(X.flatten(), axis=-1)
T = np.expand_dims(T.flatten(), axis=-1)
psi_val = analytical_solution_fun(X,T,omega)
u = np.real(psi_val)
v = np.imag(psi_val)
train_input = np.hstack((X,T))
train_output = np.hstack((u,v))
train_x = torch.tensor(train_input, dtype=torch.float32, device=device)
train_y = torch.tensor(train_output, dtype=torch.float32, device=device)
return train_x, train_y
# Define domain in code
L = float(np.pi)
omega = 1
delta_T = 0.01
delta_X = 0.01
x_dom = [-L,L]
t_dom = [0, 2*L]
analytical_solution_function = get_analytical_solution_base
test_x, test_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, analytical_solution_function)
Here delta_T and delta_X are the grid spacing in our domain. Data will be generated on this grid. The probabilty density of the QHO evolves in time and our system looks like this:

Now that we have the analytical solution, let’s build a neural network to solve it.
We will be using Mean Squared Error to quantify the difference between the true value and predicted values. It is defined as
where \(Y_i\) and \(\hat{Y_i}\) are the \(i^{\rm th}\) predicted and true values respectively. Implement this in code below:
# Exercise: Implement mse function here
def get_mse(y_true, y_pred):
# Solution:
mse = np.mean((y_true - y_pred)**2)
return mse
Fully Connected Neural Network#
A neural network consists of chained linear regression nodes (perceptrons) and activation functions. The first layer is called the input layer, the layers in the middele are called output layers and the final layer is called the output layer. A neural network surves as a function approximator between the input and the ouput.

Since neural networks are constrained to \(\mathbb{R}\), the complex valued solution can be represented as
where \(u = \operatorname{Re}(\psi)\) and \(v=\operatorname{Im}(\psi)\)
Exercise: What our input and output variable for this neural network?
Solution: Inputs: \(x,t\), Outputs: \(u,v\)
Exercise:: Write the Schrodinger equation in terms of \(u\) and \(v\)
Solution: The time-dependent Schrödinger equation can be written as
In the first case, the training data is generated on a high resolution grid from the analytical solution described above. The neural network \(\psi_{net}: \mathbb{R}^{1+1}\mapsto \mathbb{R}^{2}\) is constructed, with inputs \((x,t)\) and outputs \((u,v)\).
Let’s look at the pipeline for creating, training and testing Neural Networks. Generate training and test data:
Note: In this case, we are using the entire dataset in training for demonstrating the workflow. This is not done in practice and leads to overfitting.
L = float(np.pi)
omega = 1
# Grid spacing
delta_T = 0.1
delta_X = 0.1
# Domains
x_dom = [-L,L]
t_dom = [0, 2*L]
train_x, train_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_base)
test_x, test_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_base)
Create the architecture of Neural Network. This is a fully connected neural network (FCN):
class NN(nn.Module):
def __init__(self, n_in, n_out, n_h, n_l, activation):
super().__init__()
self.f_in = nn.Linear(n_in, n_h)
layers = []
for l in range(n_l - 1):
layers.append(nn.Linear(n_h, n_h))
layers.append(activation)
self.f_h = nn.Sequential(*layers)
self.f_out = nn.Linear(n_h, n_out)
def forward(self, x):
x = self.f_in(x)
x = activation(x)
x = self.f_h(x)
x = self.f_out(x)
return x
Create a function to train the network:
def train_nn(model, n_epochs, train_x, train_y):
optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)
loss_list = np.zeros(n_epochs)
print("Epoch \t Loss")
for i in range(n_epochs):
optimizer.zero_grad()
pred_y = model(train_x)
loss = torch.mean((train_y-pred_y)**2)
loss_list[i] = loss.detach().cpu().numpy()
loss.backward()
optimizer.step()
if i % 500 == 499:
print(f"{i} {loss}")
return model, loss_list
Create a function to quantify the loss and errors
def get_model_error(model, test_x, test_y):
model.eval()
with torch.no_grad():
pred_y = model(test_x)
pred_u, pred_v, pred_dens = get_density(pred_y)
test_u, test_v, test_dens = get_density(test_y)
loss_u = torch.mean((pred_u - test_u)**2)
loss_v = torch.mean((pred_v - test_v)**2)
loss_dens = torch.mean((pred_dens - test_dens)**2)
print(f"Model loss: \n loss_u = {loss_u} \n loss_v = {loss_v} \n loss_dens = {loss_dens}")
return pred_y
Function for inference and plotting
def inference(model, test_x, test_y,n_x, n_t, x_dom, t_dom, omega,plot_name="plot"):
model.eval()
with torch.no_grad():
pred_y = model(test_x)
pred_u, pred_v, pred_dens = get_density(pred_y)
test_u, test_v, test_dens = get_density(test_y)
loss_u = torch.mean((pred_u - test_u)**2)
loss_v = torch.mean((pred_v - test_v)**2)
loss_dens = torch.mean((pred_dens - test_dens)**2)
# print(loss_u)
# print(loss_v)
get_plots_norm_colorbar(test_y,pred_y, n_x, n_t, x_dom, t_dom, plot_name)
# return pred_y
Now that we have all the pieces in place, we can use this code to train a neural network on our domain.
torch.manual_seed(314)
activation = nn.Tanh()
model_nn = NN(2,2,20,3,activation).to(device)
n_epochs = 10000
%%time
model_nn, loss_list = train_nn(model_nn, n_epochs, train_x, train_y)
Epoch Loss
499 0.013498414307832718
999 0.004073468502610922
1499 0.0010878164321184158
1999 0.0004986620042473078
2499 0.0003609072882682085
2999 0.00021642193314619362
3499 0.00017032807227224112
3999 0.00017469754675403237
4499 0.00015739684749860317
4999 0.00010234238288830966
5499 0.00017622494488023221
5999 7.933739107102156e-05
6499 7.65430522733368e-05
6999 7.20890675438568e-05
7499 5.9130579757038504e-05
7999 5.6952234444906935e-05
8499 5.080709161120467e-05
8999 4.9290403694612905e-05
9499 4.490292485570535e-05
9999 4.5137599954614416e-05
CPU times: user 16.5 s, sys: 2.41 s, total: 18.9 s
Wall time: 27.5 s
The losses for different terms are:
pred_y = get_model_error(model_nn, test_x, test_y)
Model loss:
loss_u = 5.90107447351329e-05
loss_v = 3.179811028530821e-05
loss_dens = 3.107011070824228e-05
And we can plot our reults with the inference function
L = float(np.pi)
omega = 1
delta_T = 0.1
delta_X = 0.1
n_x = np.shape(np.arange(x_dom[0], x_dom[1], delta_X))[0]
n_t = np.shape(np.arange(t_dom[0], t_dom[1], delta_T))[0]
inference(model_nn, test_x, test_y, n_x, n_t, x_dom, t_dom, omega, 'nn')
0 finished
1 finished
2 finished
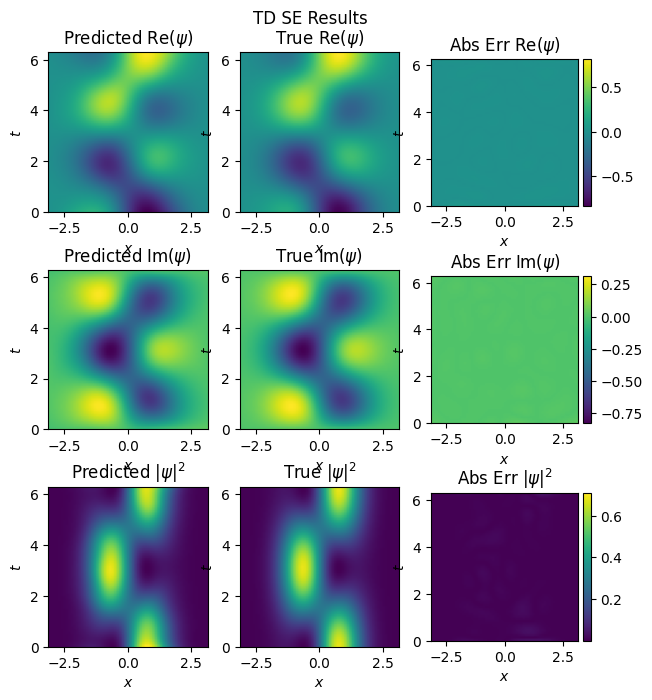
mse: u: 5.901074837311171e-05, v:3.179811028530821e-05
Reading these snapshot plots: The first column consists of plots of neural network predictions The second column consists of true values and the last column is the Absolute Error between ground truth and predictions.
The rows are real(\(\psi\)), imaginary(\(\psi\)) and density \(|\psi|^2\) .
In this case, since we used all the data over the domain for training, we get great results, where the NN approximates \(\psi\) very well.
Now for a more realistic case. We might not have a lot of experimental data covering the entire domain of a system. To approximate that, let’s train a neural network on a low resolution grid in a reduced domain \(x \in [-\pi/4,\pi/4]\).
# Generate reduced training set
L = float(np.pi)
omega = 1
delta_T = 0.1
delta_X = 0.1
x_dom = [-L/4,L/4]
t_dom = [0, 2*L]
train_x, train_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_base)
We will test it’s performance on a high resolution grid across the entire domain
delta_T = 0.01
delta_X = 0.01
x_dom = [-L,L]
t_dom = [0, 2*L]
test_x, test_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_base)
torch.manual_seed(314)
activation = nn.Tanh()
model_nn = NN(2,2,20,3,activation).to(device)
n_epochs = 10000
%%time
model_nn, loss_list = train_nn(model_nn, n_epochs, train_x, train_y,)
Epoch Loss
499 0.015750188380479813
999 0.0018576659495010972
1499 0.0009575225412845612
1999 0.0005286851665005088
2499 0.00033020987757481635
2999 0.00021686199761461467
3499 0.0001539489021524787
3999 0.00011230769450776279
4499 8.779514610068873e-05
4999 6.987732922425494e-05
5499 5.587201667367481e-05
5999 0.00016461162886116654
6499 3.714773993124254e-05
6999 3.1402007152792066e-05
7499 2.6559549951343797e-05
7999 2.3899936422822066e-05
8499 2.048485475825146e-05
8999 1.8221049685962498e-05
9499 1.6459312973893248e-05
9999 2.7384965505916625e-05
CPU times: user 9.69 s, sys: 1.08 s, total: 10.8 s
Wall time: 20 s
So far so good, the training loss is small. But across the entire domain, the loss is:
y_pred = get_model_error(model_nn, test_x, test_y)
Model loss:
loss_u = 0.06876545399427414
loss_v = 0.2319084107875824
loss_dens = 0.584796130657196
The error is orders of magnitude higher than our data point values! Let’s look at the plots:
L = float(np.pi)
omega = 1
delta_T = 0.01
delta_X = 0.01
n_x = np.shape(np.arange(x_dom[0], x_dom[1], delta_X))[0]
n_t = np.shape(np.arange(t_dom[0], t_dom[1], delta_T))[0]
inference(model_nn, test_x, test_y, n_x, n_t, x_dom, t_dom, omega, 'nn_reduced')
0 finished
1 finished
2 finished
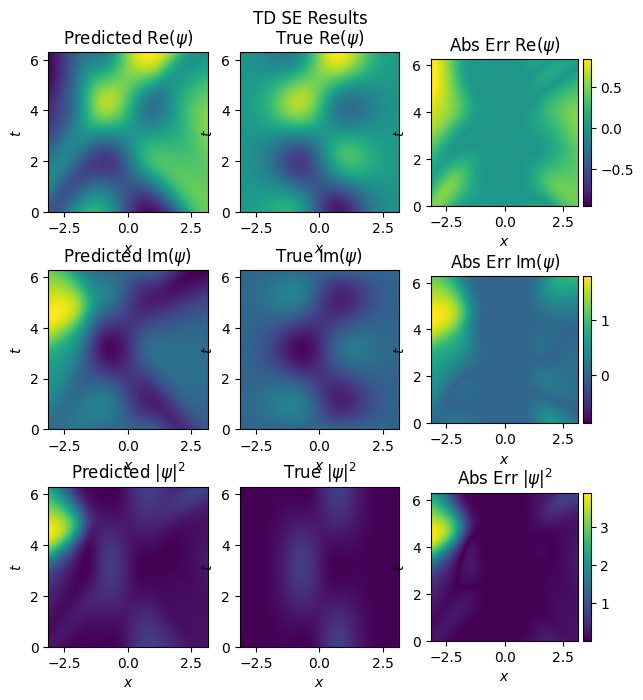
mse: u: 0.06876545399427414, v:0.23190835118293762
The values are similar in the domain that we trained on \(x \in [-0.78,0.78]\) but diverge considerably near the boundaries.
To tackle this problem, we will add some information about the governing equation in the neural network.
Physics-Informed Neural Network#
Physics Informed Neural Networks are constructed by encoding the constraints posed by a given differential equation and its boundary conditions into the loss function of a Fully Connected Network. This constraint guides the network to approximate the solution of the differential equation.
For a system \(f\), with solution \(u(\mathbf{x},t)\), governed by the following equation
where \(\mathcal{N}[u;\lambda]\) is a differential operator parameterised by \( \lambda \), \( \Omega \in \mathbb{R^D} \), \( \mathbf{x} = (x_1,x_2,...,x_d) \) with boundary conditions
and initial conditions

A neural network \(u_{net}: \mathbb{R}^{D+1}\mapsto \mathbb{R}^{1}\) is constructed as a surrogate model for the true solution \(u\),
The constraints imposed by the system are encoded in the loss term \(L\) for neural network optimisation
where \(L_{f}\) denotes the error in the solution within the interior points of the system, enforcing the PDE. This error is calculated for \(N_f\) collocation points.
\(L_{BC}\) and \(L_{IC}\) represent the constraints imposed by the boundary and initial conditions, calculated on a set of \(N_{BC}\) boundary points and \(N_{IC}\) initial points respectively, with \(u_i\) being the ground truth.

Once sufficiently trained, the network can be used as a solver for the PDE, potentially for a range of parameters \( \lambda \).
Since PINNs can be used to solve systems of arbitrary resolutions once they are trained and generalise well over different parameter spaces, they might be used to accelerate the solution of PDEs.
The following function creates the collocation points for the equation, boundary and initial conditions.
def get_physics_colloc_points(x_dom, t_dom, delta_X, delta_T,analytical_solution_function):
x = np.arange(x_dom[0], x_dom[1], delta_X).astype(float)
t = np.arange(t_dom[0], t_dom[1], delta_T).astype(float)
X, T = np.meshgrid(x, t)
x_physics = np.expand_dims(X.flatten(), axis=-1)
t_physics = np.expand_dims(T.flatten(), axis=-1)
x_physics = torch.tensor(x_physics, dtype=torch.float32, device=device).requires_grad_(True)
t_physics = torch.tensor(t_physics, dtype=torch.float32, device=device).requires_grad_(True)
f_colloc = torch.hstack((x_physics, t_physics)).to(device)
t_ic = np.zeros_like(x)
X_ic, T_ic = np.meshgrid(x, t_ic)
x_ic = np.expand_dims(X_ic.flatten(), axis=-1)
t_ic = np.expand_dims(T_ic.flatten(), axis=-1)
ic_sol = analytical_solution_function(x_ic,t_ic, omega)
ic = np.hstack((np.real(ic_sol), np.imag(ic_sol)))
ic = torch.tensor(ic, dtype=torch.float32, device=device).requires_grad_(False)
x_ic = torch.tensor(x_ic, dtype=torch.float32, device=device).requires_grad_(False)
t_ic = torch.tensor(t_ic, dtype=torch.float32, device=device).requires_grad_(False)
ic_colloc = torch.hstack((x_ic, t_ic))
x_b = np.array(x_dom)
X_b, T_b = np.meshgrid(x_b, t)
x_b = np.expand_dims(X_b.flatten(), axis=-1)
t_b = np.expand_dims(T_b.flatten(), axis=-1)
x_b = torch.tensor(x_b, dtype=torch.float32, device=device).requires_grad_(False)
t_b = torch.tensor(t_b, dtype=torch.float32, device=device).requires_grad_(False)
b_colloc = torch.hstack((x_b, t_b))
return x_physics, t_physics,f_colloc, b_colloc, ic_colloc, ic
omega = 1
x_dom = [-L,L]
t_dom = [0,2*L]
delta_x = 0.2
delta_t = 0.2
analytical_solution_function = get_analytical_solution_base
x_physics, t_physics, f_colloc, b_colloc, ic_colloc, ic = get_physics_colloc_points(x_dom, t_dom, delta_x, delta_t, analytical_solution_function)
Exercise: What will the loss terms look like in this case?
Hint: Split the Schrodinger equation in real and imaginary parts to calculate the equation loss.
Solution: The time-dependent Schrödinger equation can be written as
The loss function \(L\) is given by
At each training step, the loss function is calculated on \(N_f\) collocation points, sampled randomly from the grid.
We need to modify the training loop to calculate the new physics informed loss function:
def train_pinn(model, n_epochs, train_x, train_y, x_physics, t_physics, f_colloc, b_colloc, ic_colloc, ic):
optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)
loss_list = np.zeros(n_epochs)
print("Epoch \t Loss \t PDE Loss")
for i in range(n_epochs):
optimizer.zero_grad()
y_pred = model(train_x)
loss1 = torch.mean((y_pred-train_y)**2)
# calculate loss on colloc points
y_pred = model(f_colloc)
u = y_pred[:,0]
v = y_pred[:,1]
du_dx = torch.autograd.grad(u, x_physics, torch.ones_like(u), create_graph=True)[0]
du_dxx = torch.autograd.grad(du_dx, x_physics, torch.ones_like(du_dx), create_graph=True)[0]
du_dt = torch.autograd.grad(u, t_physics, torch.ones_like(y_pred[:,0]), create_graph=True)[0]
if debug:
print("flag_2")
dv_dx = torch.autograd.grad(v, x_physics, torch.ones_like(v), create_graph=True)[0]
dv_dxx = torch.autograd.grad(dv_dx, x_physics, torch.ones_like(dv_dx), create_graph=True)[0]
dv_dt = torch.autograd.grad(v, t_physics, torch.ones_like(v), create_graph=True)[0]
if debug:
print("flag_3")
loss_u = -du_dt - 1/2 * (dv_dxx + omega**2/2 * x_physics**2) * v.view(-1,1)
loss_v = -dv_dt + 1/2 * (du_dxx + omega**2/2 * x_physics**2) * u.view(-1,1)
loss_physics = torch.stack((loss_u, loss_v))
if debug:
print("flag_4")
y_pred_b = model(b_colloc)
y_pred_ic = model(ic_colloc)
if debug:
print("flag_5")
loss_b = torch.mean(y_pred_b**2)
loss_ic = torch.mean((y_pred_ic - ic)**2)
loss2 = (torch.mean(loss_physics**2) + loss_b + loss_ic)
if debug:
print("flag_6")
loss = loss1 + (1e-4) * loss2# add two loss terms together
loss_list[i] = loss.detach().cpu().numpy()
loss.backward()
optimizer.step()
if debug:
print("flag_7")
if i % 500 == 499:
print(f"{i} {loss} {loss2}")
return model, loss_list
We will now train the PINN on the same reduced domain
debug = False
torch.manual_seed(123)
activation = nn.Tanh()
n_epochs = 10000
model_pinn = NN(2,2,32,3,activation).to(device)
model_pinn, loss_pinn = train_pinn(model_pinn, n_epochs, train_x, train_y, x_physics, t_physics, f_colloc, b_colloc, ic_colloc, ic)
Epoch Loss PDE Loss
499 0.008926646783947945 0.28188958764076233
999 0.0012333638733252883 0.4199943244457245
1499 0.0005726434173993766 0.3827202320098877
1999 0.00034458161098882556 0.327149361371994
2499 0.00023485839483328164 0.29198330640792847
2999 0.00020212492381688207 0.26468604803085327
3499 0.00014241966709960252 0.24606826901435852
3999 0.00014419498620554805 0.23367132246494293
4499 0.00010367227514507249 0.22502441704273224
4999 9.233881428372115e-05 0.21945340931415558
5499 8.249304664786905e-05 0.21521428227424622
5999 0.000936937693040818 0.2153705507516861
6499 6.845973257441074e-05 0.2089444398880005
6999 6.363618740579113e-05 0.20560388267040253
7499 0.00014055418432690203 0.20378929376602173
7999 0.00013432957348413765 0.19779929518699646
8499 6.961895996937528e-05 0.19670142233371735
8999 4.9064241466112435e-05 0.19557559490203857
9499 4.6625933464383706e-05 0.1933160424232483
9999 4.3985033698845655e-05 0.19175738096237183
y_pred = get_model_error(model_pinn, test_x, test_y)
Model loss:
loss_u = 0.006335519719868898
loss_v = 0.005522178020328283
loss_dens = 0.0012121315812692046
L = float(np.pi)
omega = 1
delta_T = 0.01
delta_X = 0.01
n_x = np.shape(np.arange(x_dom[0], x_dom[1], delta_X))[0]
n_t = np.shape(np.arange(t_dom[0], t_dom[1], delta_T))[0]
inference(model_pinn, test_x, test_y, n_x, n_t, x_dom, t_dom, omega, 'pinn_reduced')
0 finished
1 finished
2 finished
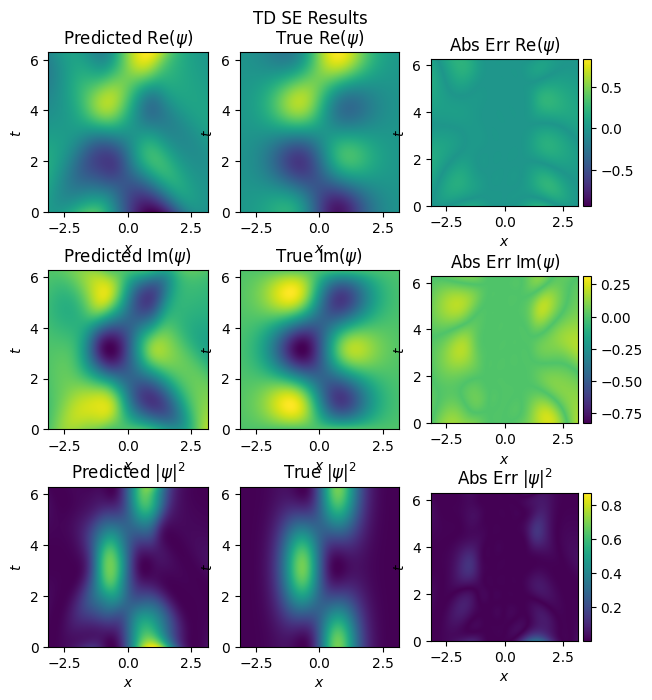
mse: u: 0.006335521582514048, v:0.005522179417312145
The PINN model matches the system well, even when trained on reduced data.
Training Considerations#
Architecture#
The architecture and associated hyperparameters have significant impact on the performance of the PINN. The learning model architecture can be customized depending on the nature of the domain. For example, CNNs, RNNs and GNNs can be used for spatial, temporal and interacting problems respectively. For the one-dimensional quantum harmonic oscillator workflow, we use a FCN with 3 layers of 20 neurons each.
Optimizer selection is important for convergence of the learner and to avoid solutions at local minima. It has been shown that a combination of Adam at early training and L-BFGS for later stages has been effective for solving a variety of PDEs through PINNs. We use the Adam optimizer only given the relatively simple nature of this problem.
Exercise: Try running the PINN with ReLU activation function. What are your observations? Why would this activation function not work?
Solution: As we saw in calculating the residual, the choice of activation functions is constrained by the fact that they have to be \((n+1)\)-differentiable for \(n\)-order PDEs. For the one-dimensional quantum harmonic oscillator problem we use \(\tanh\) activation functions because they are 3-differentiable.
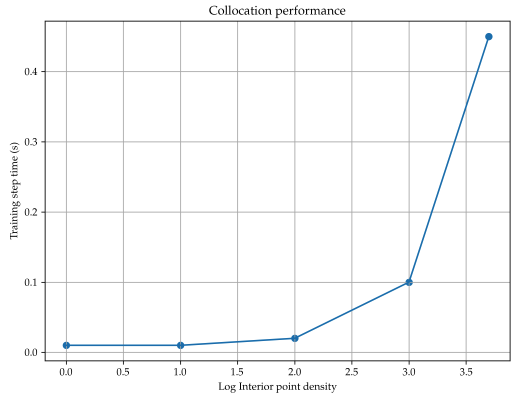
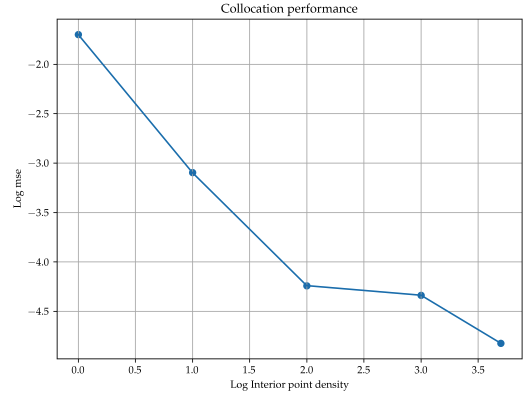
Collection Points#
The accuracy of the NN increases with increase in density of collocation points. However, the computational resources required also increases exponentially with the increase in density of points. This can lead to training bottlenecks, especially for high dimensional systems. A trade-off has to be made between the desired accuracy and number of collocation points because training the NN on a large number of points may lead to overfitting and adversely affect generalisability. The distribution of points can also be customised according to the problem domain. Density could be increased around areas of sharp discontinuities to capture more information about the domain.
Exercise: What is the effect of changing density collocation points on the training time and accuracy of the Neural Network? You can run it multiple times with different grids of collocation point to observe this.
Solution: Training time and accuracy both increase exponentially with collocation grid size.
Higher Energy States#
We will now check the performance of NNs on systems with higher energy states. For demonstration, the system used is \(\psi_{1,3}(x,t)\). The analytic solution is implemented in the method below (I will leave it to you to derive it)
Let’s write some code to compute it for arbitrary values of \(x,t,\omega\)
def get_analytical_solution_1_3(X,T, omega):
#Solution:
phi_0 =(omega / np.pi) ** (1. / 4.) * np.exp(-X * omega * X / 2.0)
phi_1 = phi_0 * np.sqrt(omega / 2.) * 2.0 * X
phi_3 = phi_0 * 1/np.sqrt(48) * (8. * omega**(3./2.) * X**3. - 12. * omega**(1./2.) * X)
psi = np.sqrt(1. / 2.) * (np.exp(-1j * 3./2. * omega * T) * phi_1 + np.exp(-1j * 7./2. * omega * T) * phi_3)
return psi
You can explore the system here:

Using a reduced grid with Fully Connected Network, we have
L = float(np.pi)
omega = 1
delta_T = 0.1
delta_X = 0.1
x_dom = [-L/4,L/4]
t_dom = [0, 2*L]
train_x, train_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_1_3)
delta_T = 0.01
delta_X = 0.01
x_dom = [-L,L]
t_dom = [0, 2*L]
test_x, test_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_1_3)
torch.manual_seed(314)
activation = nn.Tanh()
model_nn_he = NN(2,2,32,3,activation).to(device)
optimizer = torch.optim.Adam(model_nn_he.parameters(),lr=1e-3)
n_epochs = 10000
%%time
model_nn_he, loss_list = train_nn(model_nn_he, n_epochs, train_x, train_y)
Epoch Loss
499 0.031224453821778297
999 0.028855865821242332
1499 0.027397828176617622
1999 0.025098711252212524
2499 0.020609499886631966
2999 0.012454207986593246
3499 0.008661504834890366
3999 0.006156652234494686
4499 0.004363080952316523
4999 0.004531885962933302
5499 0.002276886021718383
5999 0.0017896972130984068
6499 0.0014302479103207588
6999 0.0011012511095032096
7499 0.0008160155266523361
7999 0.0006448206841014326
8499 0.0005309513653628528
8999 0.00045337286428548396
9499 0.0004067313566338271
9999 0.00035199103876948357
CPU times: user 10.5 s, sys: 1.08 s, total: 11.6 s
Wall time: 20.5 s
y_pred = get_model_error(model_nn_he, test_x, test_y)
Model loss:
loss_u = 0.3241112530231476
loss_v = 0.29832813143730164
loss_dens = 1.082219123840332
L = float(np.pi)
omega = 1
delta_T = 0.01
delta_X = 0.01
n_x = np.shape(np.arange(x_dom[0], x_dom[1], delta_X))[0]
n_t = np.shape(np.arange(t_dom[0], t_dom[1], delta_T))[0]
inference(model_nn_he, test_x, test_y, n_x, n_t, x_dom, t_dom, omega, 'high_nn')
0 finished
1 finished
2 finished
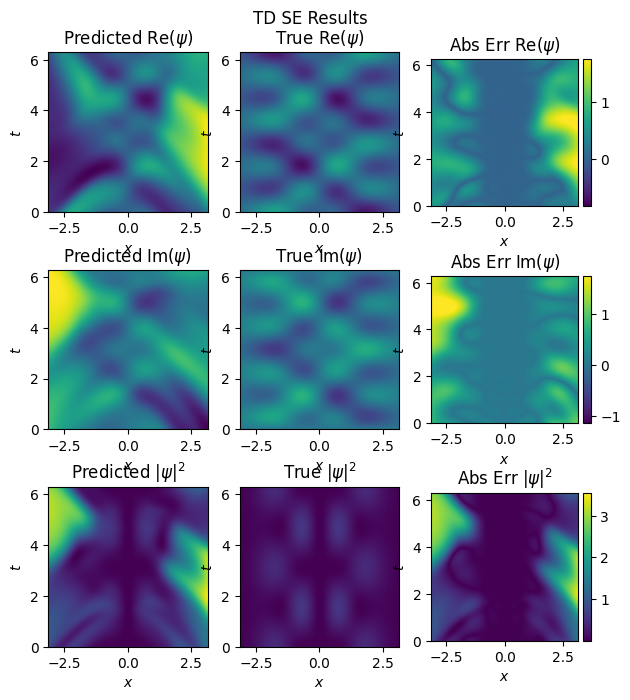
mse: u: 0.3241112530231476, v:0.29832807183265686
This does not capture any detail beyond the domain, as seen in Abs Err plots. Now for PINNs:
omega = 1
x_dom = [-L,L]
t_dom = [0,2*L]
delta_x = 0.2
delta_t = 0.2
analytical_solution_function = get_analytical_solution_1_3
x_physics, t_physics, f_colloc, b_colloc, ic_colloc, ic = get_physics_colloc_points(x_dom, t_dom, delta_x, delta_t, analytical_solution_function)
debug = False
torch.manual_seed(314)
activation = nn.Tanh()
n_epochs = 10000
model_pinn_he = NN(2,2,32,3,activation).to(device)
model_pinn_he, loss_pinn = train_pinn(model_pinn_he, n_epochs, train_x, train_y, x_physics, t_physics, f_colloc, b_colloc, ic_colloc, ic)
Epoch Loss PDE Loss
499 0.03161158040165901 0.8634124994277954
999 0.02884337492287159 0.6241305470466614
1499 0.027154264971613884 0.47471410036087036
1999 0.024984028190374374 0.36618152260780334
2499 0.019856346771121025 0.37359610199928284
2999 0.012240186333656311 0.5774284601211548
3499 0.00744221406057477 0.7774415016174316
3999 0.0052307541482150555 0.8842865824699402
4499 0.004062865395098925 1.0490221977233887
4999 0.0032787614036351442 1.1604061126708984
5499 0.002712646732106805 1.204504370689392
5999 0.0022097593173384666 1.2456035614013672
6499 0.010788897052407265 1.2619657516479492
6999 0.001292745117098093 1.0734755992889404
7499 0.0010441206395626068 0.9782638549804688
7999 0.0008778434712439775 0.8859479427337646
8499 0.0007557199569419026 0.7998067140579224
8999 0.0024503038730472326 0.7007265686988831
9499 0.0005588126368820667 0.6521516442298889
9999 0.0005486407317221165 0.597593367099762
y_pred = get_model_error(model_pinn_he, test_x, test_y)
Model loss:
loss_u = 0.060529790818691254
loss_v = 0.05063500627875328
loss_dens = 0.023826157674193382
L = float(np.pi)
omega = 1
delta_T = 0.01
delta_X = 0.01
n_x = np.shape(np.arange(x_dom[0], x_dom[1], delta_X))[0]
n_t = np.shape(np.arange(t_dom[0], t_dom[1], delta_T))[0]
test_x, test_y = get_data_set(x_dom, t_dom, delta_X, delta_T, omega, get_analytical_solution_1_3)
inference(model_pinn_he, test_x, test_y, n_x, n_t, x_dom, t_dom, omega, 'high_pinn')
0 finished
1 finished
2 finished
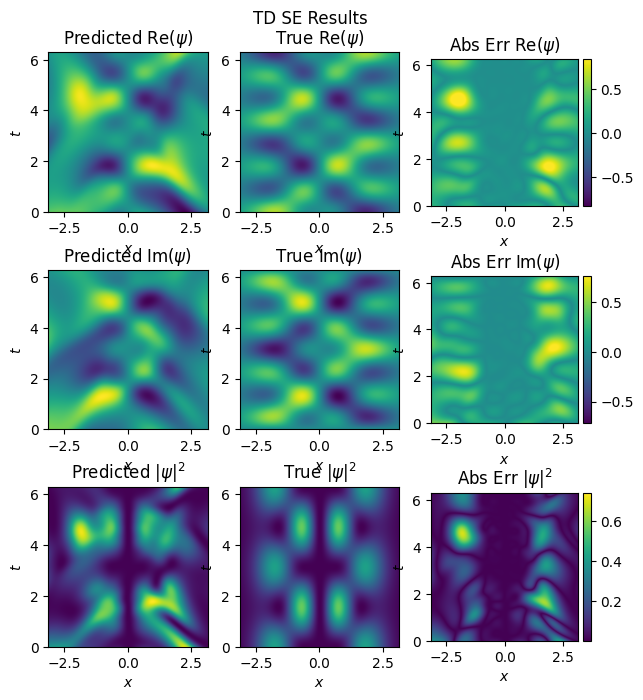
mse: u: 0.06052980571985245, v:0.050635021179914474
For higher energy states, it is difficult to capture the details with fully connected layers. PINNs can be extended with Recurrent Neural Networks to tackle this.
Some Project Ideas#
Experiment with different layer types for the higher energy states. One particular layer that might be useful would be gru layer (https://pytorch.org/docs/stable/generated/torch.nn.GRU.html). These layers are used for time series forecasting in Recurrent Neural Networks, which might be helpful for our time dependent system.
You can also use causal training loss for the higer energy states. The loss we have been using so far does not take causality into account. For a causal loss function, we divide the domain into consecutive time chunks and use a weighted sum of losses that enforces order in time. You can read more about it here:
Modify the PINNs to work with 2D QHO system Hint: Since this is a separable system, we can extend it to 2D as follow: $\( \Large \phi_n = \phi_n(x)\phi_n(y) \)$
Can the neural network generalize over other parameters as well? Add \(\omega\) as an input to the neural network and train it to work with a range of \(\omega\) values.
Implement this network for other systems such as infinite square well.
Acknowledgments#
Initial version: Mark Neubauer
From APS GDS repository
© Copyright 2026