Simulation Based Inference#
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader, random_split
import numpy as np
import emcee
from scipy.stats import poisson
from scipy.stats import chi2
from scipy.optimize import basinhopping
from tqdm import tqdm
import matplotlib.pyplot as plt
import pytorch_lightning as pl
import corner
Introduction#
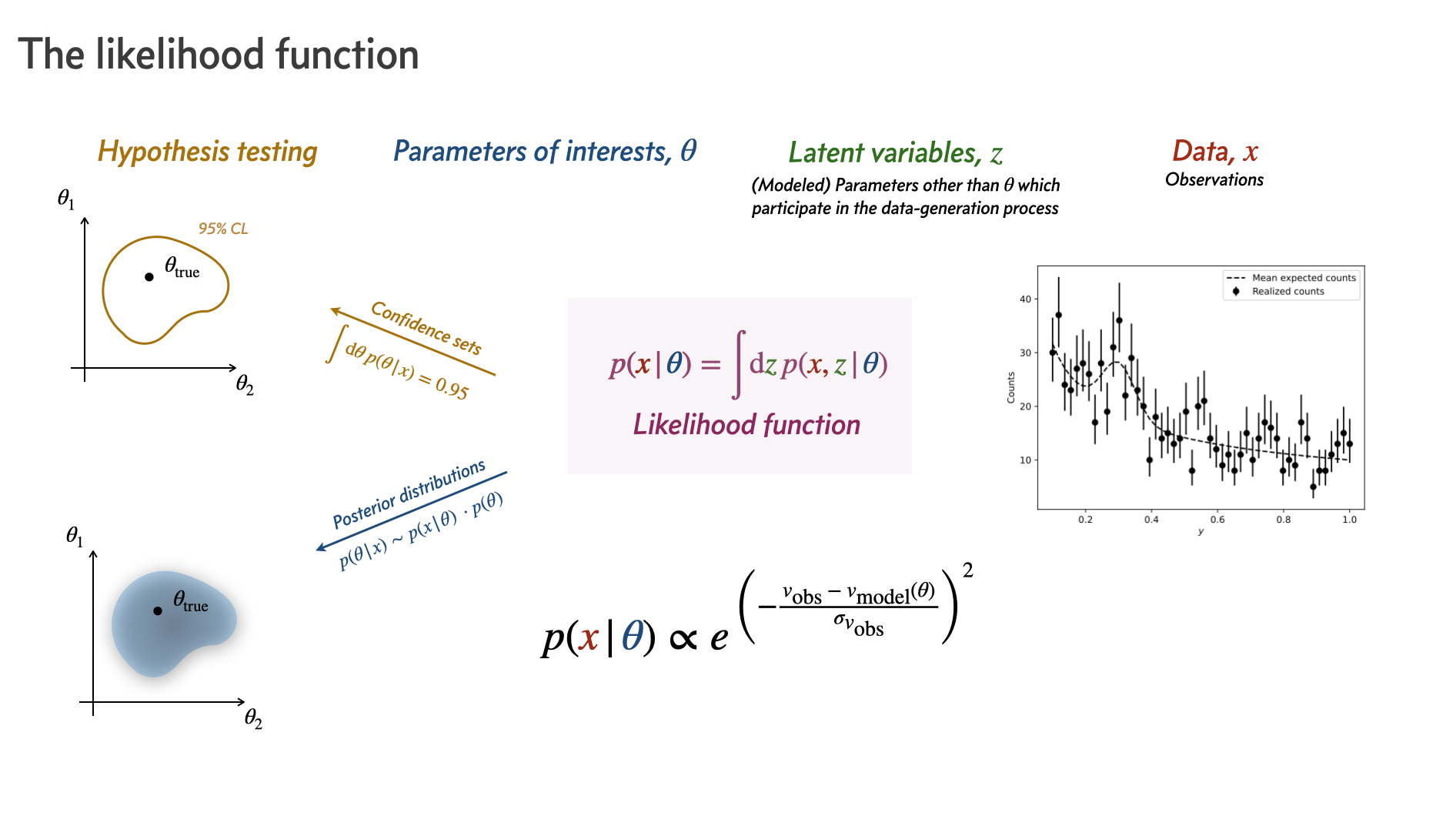
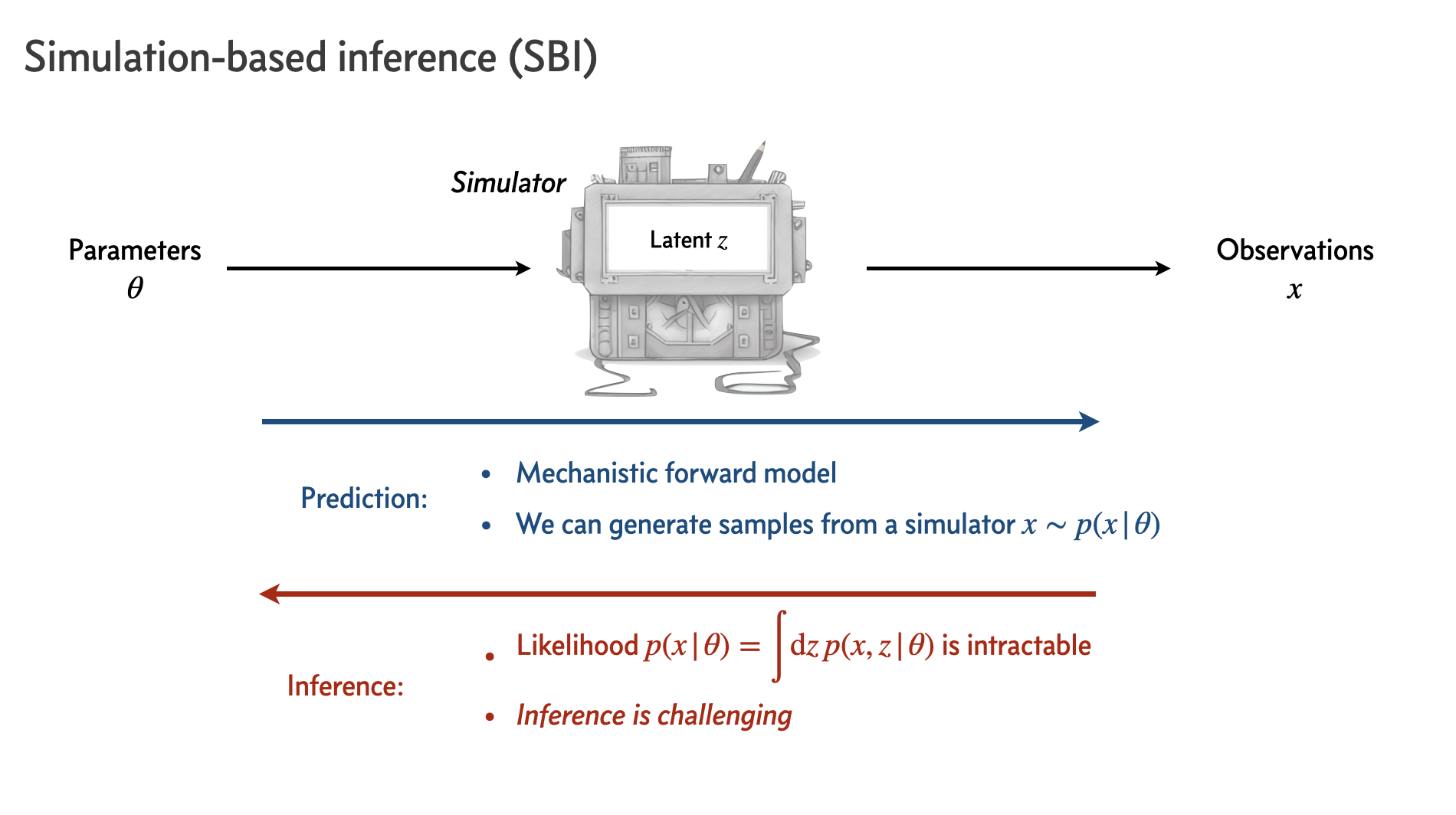
Simulation-based inference (SBI) is a powerful class of methods for performing inference in settings where the likelihood is computationally intractable, but simulations can be realized via forward modeling.
In this lecture we will
Introduce the notion of an implicit likelihood, and how to leverage it to perform inference;
Look at a “traditional” method for likelihood-free inference: Approximate Bayesian Computation (ABC);
Build up two common modern neural SBI techniques: neural likelihood-ratio estimation (NRE) and neural posterior estimation (NPE);
Introduce the concept of statistical coverage testing and calibration.
As examples, we will look at a simple Gaussian-signal-on-power-law-background (“bump hunt”), where the likelihood is tractable, and a more complicated example of inferring a distribution of point sources, where the likelihood is computationally intractable. We will emphasize what it means for a likelihood to be computationally intractable/challenging and where the advantages of SBI come in.
Simple Bump-on-Power-Law Example#
As an initial example, consider a Gaussian signal parameterized by {amplitude, mean location, std} on top of a power law background parameterize by {amplitude, power-law exponent}.
def bump_forward_model(y, amp_s, mu_s, std_s, amp_b, exp_b):
""" Forward model for a Gaussian bump (amp_s, mu_s, std_s) on top of a power-law background (amp_b, exp_b).
"""
x_b = amp_b * (y ** exp_b) # Power-law background
x_s = amp_s * np.exp(-((y - mu_s) ** 2) / (2 * std_s ** 2)) # Gaussian signal
x = x_b + x_s # Total mean signal
return x
def poisson_interval(k, alpha=0.32):
""" Uses chi2 to get the poisson interval.
"""
a = alpha
low, high = (chi2.ppf(a/2, 2*k) / 2, chi2.ppf(1-a/2, 2*k + 2) / 2)
if k == 0:
low = 0.0
return k - low, high - k
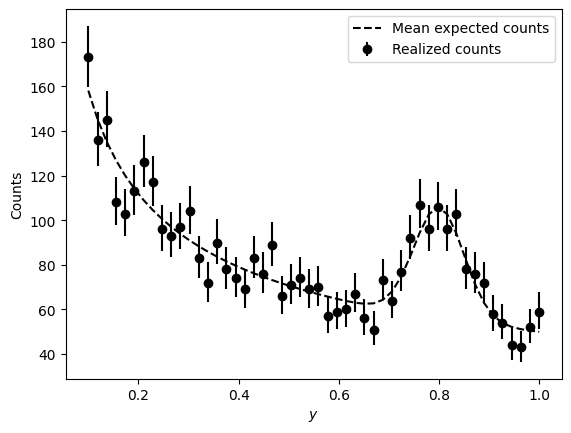
y = np.linspace(0.1, 1, 50) # Dependent variable
# Mean expected counts
x_mu = bump_forward_model(y,
amp_s=50, mu_s=0.8, std_s=0.05, # Signal params
amp_b=50, exp_b=-0.5) # Background params
# Realized counts
x = np.random.poisson(x_mu)
x_err = np.array([poisson_interval(k) for k in x.T]).T
# Plot
plt.plot(y, x_mu, color='k', ls='--', label="Mean expected counts")
plt.errorbar(y, x, yerr=x_err, fmt='o', color='k', label="Realized counts")
plt.xlabel("$y$")
plt.ylabel("Counts")
plt.legend()
plt.show()
The Explicit Likelikood#
In this case, we can write down a log-likelihood as a Poisson over the mean returned by the forward model.
def log_like(theta, y, x):
""" Log-likehood function for a Gaussian bump (amp_s, mu_s, std_s) on top of a power-law background (amp_b, exp_b).
"""
amp_s, mu_s, std_s, amp_b, exp_b = theta
mu = bump_forward_model(y, amp_s, mu_s, std_s, amp_b, exp_b)
return poisson.logpmf(x, mu).sum()
Let’s focus on just 2 parameters for simplicity, the signal amplitude and mean location. The likelihood in this case is:
def log_like_sig(params, y, x):
""" Log-likehood function for a Gaussian bump (amp_s, mu_s) on top of a fixed PL background.
"""
amp_s, mu_s = params
std_s, amp_b, exp_b = 0.05, 50, -0.5
mu = bump_forward_model(y, amp_s, mu_s, std_s, amp_b, exp_b)
return poisson.logpmf(x, mu).sum()
log_like_sig([50, 0.8], y, x)
np.float64(-175.93791395694095)
Get a maximum-liklelihood estimate:
# Initial guess for the parameters
initial_guess = [100., 0.1]
# Set up the minimizer_kwargs for the basinhopping algorithm
minimizer_kwargs = {"method": "L-BFGS-B", "bounds": ((0, 200), (0, 1))}
# Perform the optimization using basinhopping
opt = basinhopping(lambda thetas: -log_like_sig(thetas, y, x), initial_guess, minimizer_kwargs=minimizer_kwargs)
print("MLE parameters: {}; true parameters: {}".format(opt.x, (50, 0.8)))
MLE parameters: [52.47003182 0.79877118]; true parameters: (50, 0.8)
And approximate posterior using emcee:
def log_prior(thetas):
""" Log-prior function for a Gaussian bump (amp_s, mu_s) on top of a fixed PL background.
"""
amp_s, mu_s = thetas
if 0 < amp_s < 200 and 0 < mu_s < 2:
return 0
else:
return -np.inf
def log_post(thetas, y, x):
""" Log-posterior function for a Gaussian bump (amp_s, mu_s) on top of a fixed PL background.
"""
lp = log_prior(thetas)
if not np.isfinite(lp):
return -np.inf
else:
return lp + log_like_sig(thetas, y, x)
# Sampling with `emcee`
ndim, nwalkers = 2, 32
sampler = emcee.EnsembleSampler(nwalkers, ndim, log_post, args=(y, x))
pos = opt.x + 1e-3 * np.random.randn(nwalkers, ndim)
sampler.run_mcmc(pos, 5000, progress=True);
100%|██████████| 5000/5000 [00:03<00:00, 1546.42it/s]
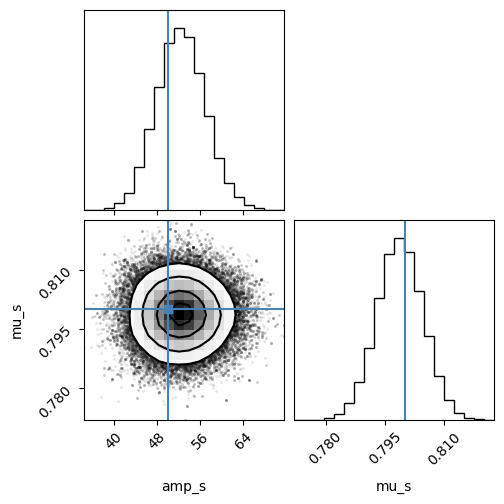
# Plot posterior samples
flat_samples = sampler.get_chain(discard=1000, flat=True)
corner.corner(flat_samples, labels=["amp_s", "mu_s"], truths=[50, 0.8], smooth=1.);
The Implicit Likelikood#
Now we will do inference without relying on the explicit likelihood evaluation. The key realization is that samples from the forward model implicitly encode the likelihood; when we are simulating data points \(x\) for different parameter points \(\theta\), we are drawing samples from the likelihood:
which is where the implicit aspect comes from. Let’s write down a bump simulator:
def bump_simulator(thetas, y):
""" Simulate samples from the bump forward model given theta = (amp_s, mu_s) and abscissa points y.
"""
amp_s, mu_s = thetas
std_s, amp_b, exp_b = 0.05, 50, -0.5
x_mu = bump_forward_model(y, amp_s, mu_s, std_s, amp_b, exp_b)
x = np.random.poisson(x_mu)
return x
# Test it out
bump_simulator([50, 0.8], y)
array([154, 156, 133, 119, 116, 121, 111, 128, 95, 95, 93, 86, 82,
95, 83, 81, 92, 64, 68, 69, 82, 60, 63, 80, 67, 76,
57, 68, 65, 62, 55, 59, 63, 60, 74, 63, 96, 86, 115,
90, 91, 66, 71, 59, 47, 46, 48, 49, 60, 49])
Approximate Bayesian Computation#
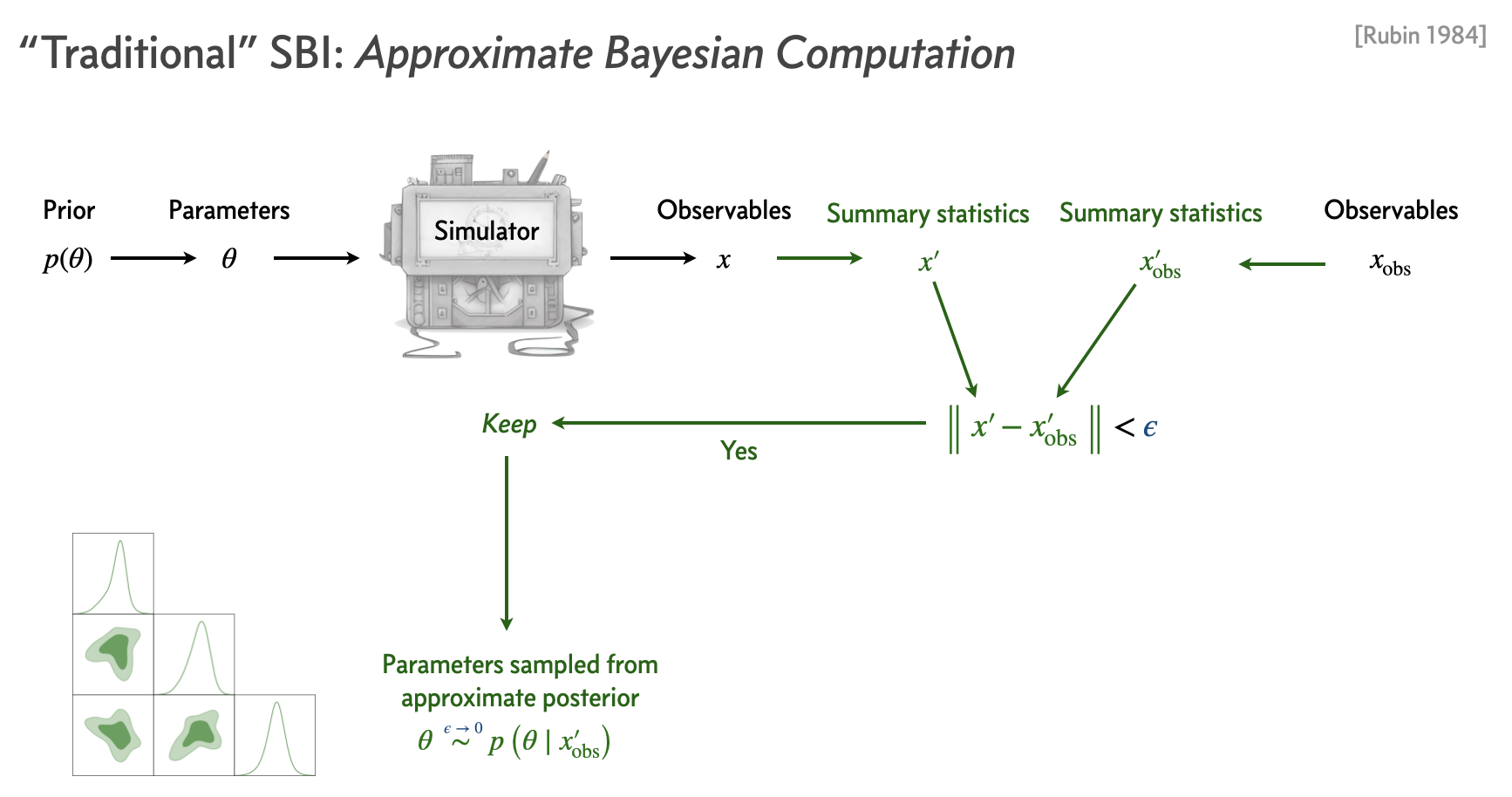
The idea behind Approximate Bayesian Computation (ABC) is to realize samples from the forward model (with the parameters \(\theta\) drawn from a prior) and compare it to the dataset of interest \(x\). If the data and realized samples are close enough to each other according to some criterion, we keep the parameter points.
The comparison criterion here is a simple MSE on the data points. Play around with the parameters of the forward model to see how the criterion eps changes.
x_fwd = bump_simulator([50, 0.8], y)
eps = np.sum(np.abs(x - x_fwd) ** 2) / len(x)
eps
np.float64(125.06)
def abc(y, x, eps_thresh=500., n_samples=1000):
"""ABC algorithm for Gaussian bump model.
Args:
y (np.ndarray): Abscissa points.
x (np.ndarray): Data counts.
eps_thresh (float, optional): Acceptance threshold. Defaults to 500.0.
n_samples (int, optional): Number of samples after which to stop. Defaults to 1000.
Returns:
np.ndarray: Accepted samples approximating the posterior p(theta|x).
"""
samples = []
total_attempts = 0
progress_bar = tqdm(total=n_samples, desc="Accepted Samples", unit="samples")
# Keep simulating until we have enough accepted samples
while len(samples) < n_samples:
params = np.random.uniform(low=[0, 0], high=[200, 1]) # Priors; theta ~ p(theta)
x_fwd = bump_simulator(params, y) # x ~ p(x|theta)
eps = np.sum(np.abs(x - x_fwd) ** 2) / len(x) # Distance metric; d(x, x_fwd)
total_attempts += 1
# If accepted, add to samples
if eps < eps_thresh:
samples.append(params)
progress_bar.update(1)
acceptance_ratio = len(samples) / total_attempts
progress_bar.set_postfix(acceptance_ratio=f"{acceptance_ratio:.3f}")
progress_bar.close()
return np.array(samples)
n_samples = 5_000
post_samples = abc(y, x, eps_thresh=200, n_samples=n_samples)
Accepted Samples: 100%|██████████| 5000/5000 [00:06<00:00, 753.63samples/s, acceptance_ratio=0.012]
fig = corner.corner(post_samples, labels=["amp_s", "mu_s"], truths=[50, 0.8], range=[(0, 200), (0.3, 1)], bins=50);
corner.corner(flat_samples, labels=["amp_s", "mu_s"], truths=[50, 0.8], fig=fig, color="red", weights=np.ones(len(flat_samples)) * n_samples / len(flat_samples), range=[(0, 200), (0.3, 1)], bins=50);
WARNING:root:Too few points to create valid contours
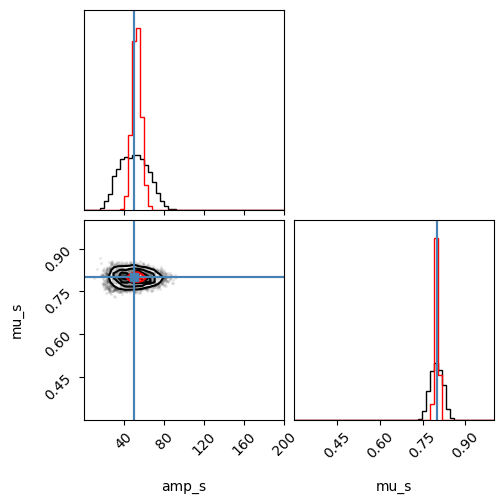
Downsides of vanilla ABC:
How to summarize the data? Curse of dimensionality / loss of information.
How to compare with data? Likelihood may not be available.
Choice of acceptance threshold: Precision/efficiency tradeoff.
Need to re-run pipeline for new data or new prior.
Neural Likelihood-ratio Estimation#
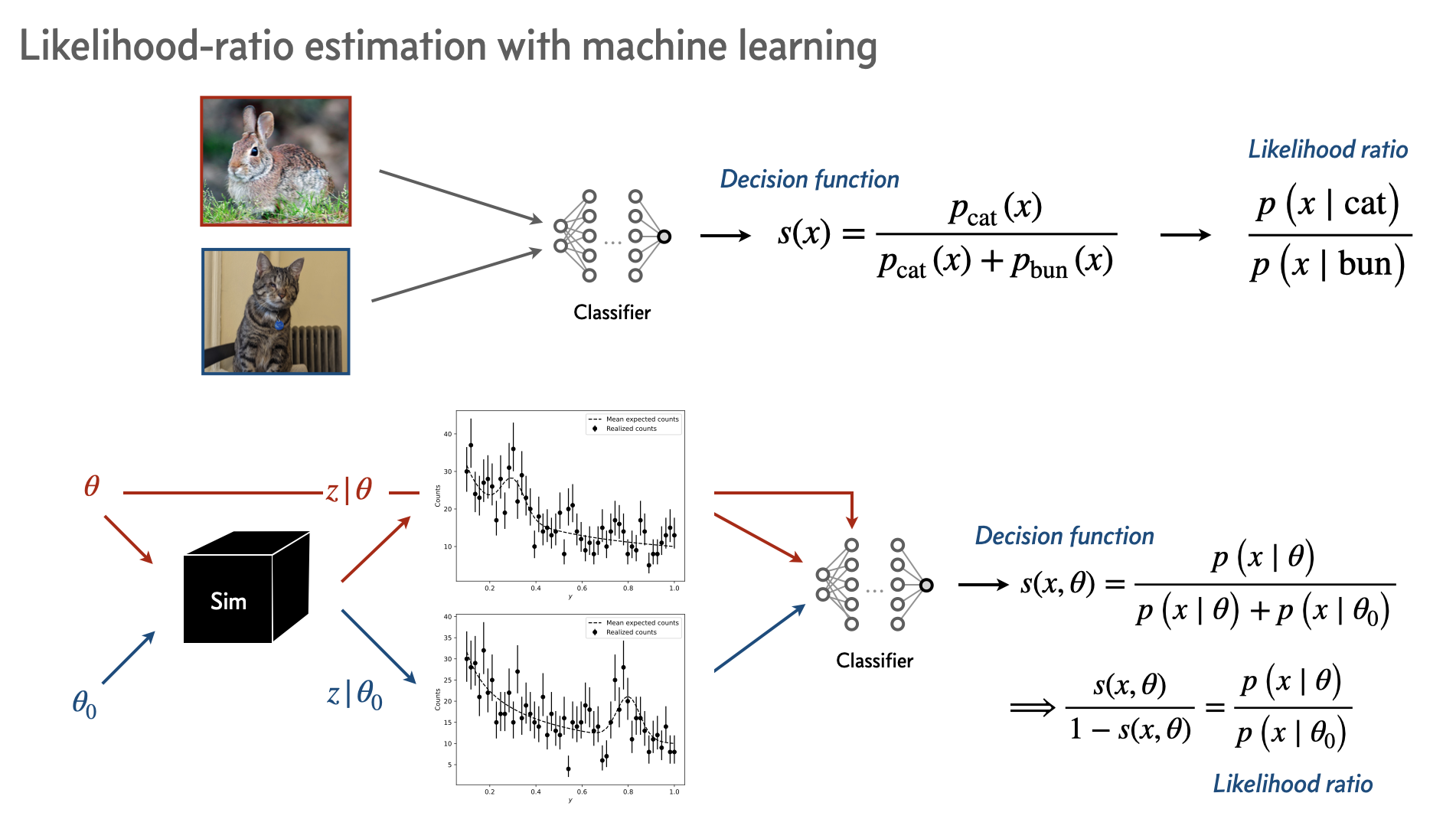
For numerical stability, the alternate hypothesis \(\theta_0\) can be assumed to be one where \(x\) and \(\theta\) are not correlated, i.e., drawn from the individual marginal distributions \(\{x, \theta\} \sim p(x)\,p(\theta)\). Then the alternate has support over the entire parameter space, instead of being a single hypothesis \(\theta_0\).
In this case, we get the likelihood-to-evidence ratio,
\(\hat r(x, \theta)\) can be shown to be the classifier logit, i.e. the output before softmaxxing into the decision function with range between 0 and 1.
Start by creating some training data.
n_train = 50_000
# Simulate training data
theta_samples = np.random.uniform(low=[0, 0], high=[200, 1], size=(n_train, 2)) # Parameter proposal
x_samples = np.array([bump_simulator(theta, y) for theta in tqdm(theta_samples)])
# Convert to torch tensors
theta_samples = torch.tensor(theta_samples, dtype=torch.float32)
x_samples = torch.tensor(x_samples, dtype=torch.float32)
# Normalize the data
x_mean = x_samples.mean(dim=0)
x_std = x_samples.std(dim=0)
x_samples = (x_samples - x_mean) / x_std
theta_mean = theta_samples.mean(dim=0)
theta_std = theta_samples.std(dim=0)
theta_samples = (theta_samples - theta_mean) / theta_std
100%|██████████| 50000/50000 [00:00<00:00, 103379.07it/s]
As our parameterized classifier, we will use a simple MLP.
def build_mlp(input_dim, hidden_dim, output_dim, layers, activation=nn.GELU()):
"""Create an MLP from the configuration."""
seq = [nn.Linear(input_dim, hidden_dim), activation]
for _ in range(layers):
seq += [nn.Linear(hidden_dim, hidden_dim), activation]
seq += [nn.Linear(hidden_dim, output_dim)]
return nn.Sequential(*seq)
Create a neural ratio estimator class, with a corresponding loss function. The loss is a simple binary cross-entropy loss that discriminates between samples from the joint distribution \(\{x, \theta\} \sim p(x\mid\theta)\) and those from a product of marginals \(\{x, \theta\} \sim p(x)\,p(\theta)\). Samples from the latter are obtained by shuffling joint samples from within a batch.
The binary cross-entropy loss is used as the classifier loss to distinguish samples from the joint and marginals,
where \(y_i\) are the true labels and \(p_i\) the softmaxxed probabilities.
class NeuralRatioEstimator(pl.LightningModule):
""" Simple neural likelihood-to-evidence ratio estimator, using an MLP as a parameterized classifier.
"""
def __init__(self, x_dim, theta_dim):
super().__init__()
self.classifier = build_mlp(input_dim=x_dim + theta_dim, hidden_dim=128, output_dim=1, layers=4)
def forward(self, x):
return self.classifier(x)
def loss(self, x, theta):
# Repeat x in groups of 2 along batch axis
x = x.repeat_interleave(2, dim=0)
# Get a shuffled version of theta
theta_shuffled = theta[torch.randperm(theta.shape[0])]
# Interleave theta and shuffled theta
theta = torch.stack([theta, theta_shuffled], dim=1).reshape(-1, theta.shape[1])
# Get labels; ones for pairs from joint, zeros for pairs from marginals
labels = torch.ones(x.shape[0], device=x.device)
labels[1::2] = 0.0
# Pass through parameterized classifier to get logits
logits = self(torch.cat([x, theta], dim=1))
probs = torch.sigmoid(logits).squeeze()
return nn.BCELoss(reduction='none')(probs, labels)
def training_step(self, batch, batch_idx):
x, theta = batch
loss = self.loss(x, theta).mean()
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, theta = batch
loss = self.loss(x, theta).mean()
self.log("val_loss", loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=3e-4)
# Evaluate loss; initially it should be around -log(0.5) = 0.693
nre = NeuralRatioEstimator(x_dim=50, theta_dim=2)
nre.loss(x_samples[:64], theta_samples[:64])
tensor([0.7111, 0.6754, 0.7117, 0.6749, 0.7113, 0.6758, 0.7109, 0.6758, 0.7118,
0.6746, 0.7132, 0.6736, 0.7116, 0.6749, 0.7108, 0.6753, 0.7122, 0.6743,
0.7107, 0.6759, 0.7121, 0.6747, 0.7113, 0.6756, 0.7112, 0.6754, 0.7116,
0.6752, 0.7112, 0.6755, 0.7111, 0.6756, 0.7110, 0.6756, 0.7113, 0.6753,
0.7123, 0.6743, 0.7113, 0.6753, 0.7107, 0.6758, 0.7114, 0.6753, 0.7109,
0.6758, 0.7112, 0.6755, 0.7122, 0.6745, 0.7112, 0.6755, 0.7136, 0.6732,
0.7116, 0.6751, 0.7123, 0.6744, 0.7106, 0.6760, 0.7139, 0.6731, 0.7110,
0.6755, 0.7108, 0.6755, 0.7111, 0.6754, 0.7111, 0.6756, 0.7115, 0.6753,
0.7122, 0.6748, 0.7109, 0.6757, 0.7115, 0.6749, 0.7111, 0.6754, 0.7106,
0.6760, 0.7111, 0.6755, 0.7116, 0.6749, 0.7113, 0.6753, 0.7111, 0.6756,
0.7111, 0.6757, 0.7117, 0.6752, 0.7114, 0.6754, 0.7114, 0.6753, 0.7106,
0.6761, 0.7112, 0.6755, 0.7114, 0.6753, 0.7109, 0.6756, 0.7115, 0.6752,
0.7128, 0.6736, 0.7116, 0.6754, 0.7108, 0.6758, 0.7111, 0.6752, 0.7114,
0.6753, 0.7113, 0.6752, 0.7117, 0.6748, 0.7117, 0.6747, 0.7125, 0.6742,
0.7108, 0.6759], grad_fn=<BinaryCrossEntropyBackward0>)
Instantiate dataloader and train.
val_fraction = 0.1
batch_size = 128
n_samples_val = int(val_fraction * len(x_samples))
dataset = TensorDataset(x_samples, theta_samples)
dataset_train, dataset_val = random_split(dataset, [len(x_samples) - n_samples_val, n_samples_val])
train_loader = DataLoader(dataset_train, batch_size=batch_size, num_workers=8, pin_memory=True, shuffle=True)
val_loader = DataLoader(dataset_val, batch_size=batch_size, num_workers=8, pin_memory=True, shuffle=False)
trainer = pl.Trainer(max_epochs=20)
trainer.fit(model=nre, train_dataloaders=train_loader, val_dataloaders=val_loader)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/msn/repos/illinois-mlp/venv/lib/python3.12/site-packages/pytorch_lightning/trainer/connectors/logger_connector/logger_connector.py:76: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `pytorch_lightning` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
--------------------------------------------------
0 | classifier | Sequential | 73.0 K | train
--------------------------------------------------
73.0 K Trainable params
0 Non-trainable params
73.0 K Total params
0.292 Total estimated model params size (MB)
8 Modules in train mode
0 Modules in eval mode
`Trainer.fit` stopped: `max_epochs=20` reached.
The classifier logits are now an estimator for the likelihood ratio. We can write down a log-likelihood function and use it to sample from the corresponding posterior distribution, just like before.
def log_like(theta, x):
""" Log-likelihood ratio estimator using trained classifier logits.
"""
x = torch.Tensor(x)
theta = torch.Tensor(theta)
# Normalize
x = (x - x_mean) / x_std
theta = (theta - theta_mean) / theta_std
x = torch.atleast_1d(x)
theta = torch.atleast_1d(theta)
# Detach the tensor to remove it from the computation graph and get the scalar value
return nre.classifier(torch.cat([x, theta], dim=-1)).squeeze().detach().numpy()
theta_test = np.array([90, 0.8])
x_test = bump_simulator(theta_test, y)
log_like(theta_test, x_test)
array(3.7350936, dtype=float32)
def log_post(theta, x):
""" Log-posterior distribution, for sampling.
"""
lp = log_prior(theta)
if not np.isfinite(lp):
return -np.inf
else:
return lp + log_like(theta, x)
Sample with emcee:
ndim, nwalkers = 2, 32
sampler = emcee.EnsembleSampler(nwalkers, ndim, log_post, args=(x_test,))
pos = opt.x + 1e-3 * np.random.randn(nwalkers, ndim)
sampler.run_mcmc(pos, 5000, progress=True);
100%|██████████| 5000/5000 [00:15<00:00, 330.74it/s]
Plot approximate posterior:
flat_samples = sampler.get_chain(discard=1000, flat=True)
corner.corner(flat_samples, labels=["amp_s", "mu_s"], truths=[90, 0.8]);
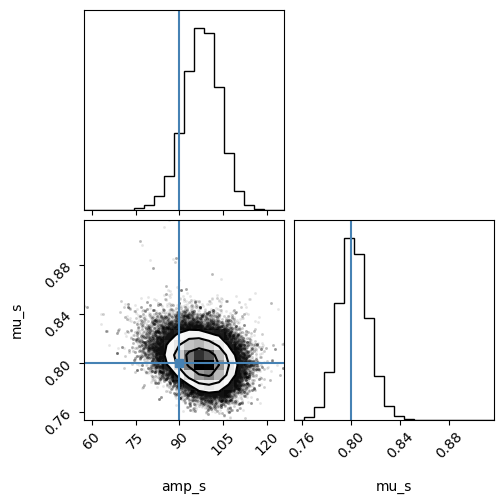
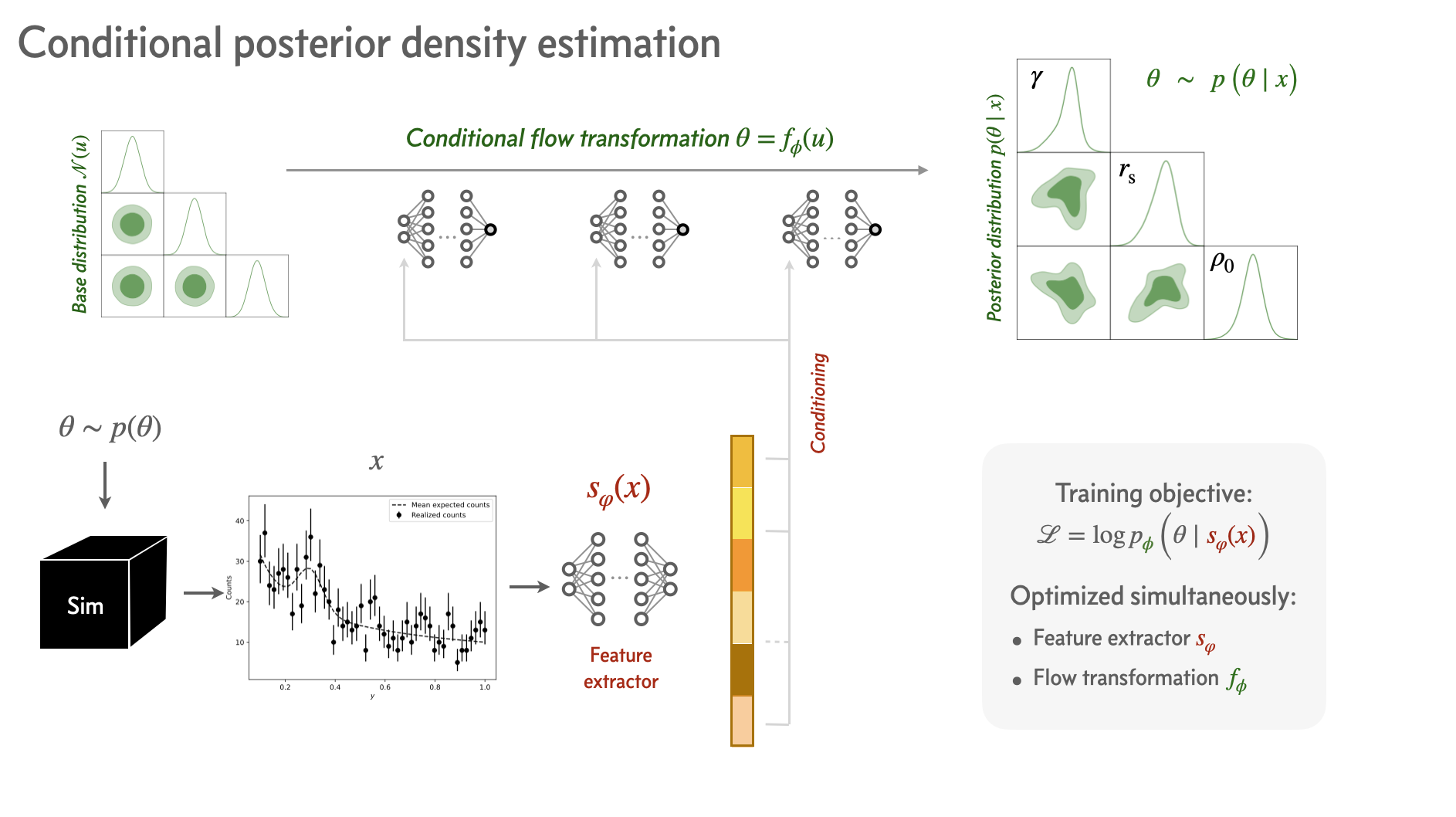
Neural Posterior Estimation#
from nflows.flows.base import Flow
from nflows.distributions.normal import StandardNormal
from nflows.transforms.base import CompositeTransform
from nflows.transforms.autoregressive import MaskedAffineAutoregressiveTransform
from nflows.transforms.permutations import ReversePermutation
def get_flow(d_in=2, d_hidden=32, d_context=16, n_layers=4):
""" Instantiate a simple (Masked Autoregressive) normalizing flow.
"""
base_dist = StandardNormal(shape=[d_in])
transforms = []
for _ in range(n_layers):
transforms.append(ReversePermutation(features=d_in))
transforms.append(MaskedAffineAutoregressiveTransform(features=d_in, hidden_features=d_hidden, context_features=d_context))
transform = CompositeTransform(transforms)
flow = Flow(transform, base_dist)
return flow
# Instantiate flow
flow = get_flow()
# Make sure sampling and log-prob calculation makes sense
samples, log_prob = flow.sample_and_log_prob(num_samples=100, context=torch.randn(2, 16))
print(samples.shape, log_prob.shape)
torch.Size([2, 100, 2]) torch.Size([2, 100])
Construct a neural posterior estimator. It uses a normalizing flow as a (conditional) posterior density estimator, and a feature-extraction network that aligns the directions of variations in parameters \(\theta\) and data \(x\).
where \(\{\phi, \varphi\}\) are the parameters of the normalizing flow and featurizer MLP, respectively.
class NeuralPosteriorEstimator(pl.LightningModule):
""" Simple neural posterior estimator class using a normalizing flow as the posterior density estimator.
"""
def __init__(self, featurizer, d_context=16):
super().__init__()
self.featurizer = featurizer
self.flow = get_flow(d_in=2, d_hidden=32, d_context=d_context, n_layers=4)
def forward(self, x):
return self.featurizer(x)
def loss(self, x, theta):
context = self(x)
return -self.flow.log_prob(inputs=theta, context=context)
def training_step(self, batch, batch_idx):
x, theta = batch
loss = self.loss(x, theta).mean()
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, theta = batch
loss = self.loss(x, theta).mean()
self.log("val_loss", loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=3e-4)
Instantiate the NPE class and look at the loss:
npe = NeuralPosteriorEstimator(featurizer=build_mlp(input_dim=50, hidden_dim=128, output_dim=16, layers=4))
npe.loss(x_samples[:64], theta_samples[:64])
tensor([4.5507, 4.5462, 4.8587, 4.7216, 5.1465, 5.2831, 4.3842, 5.0363, 4.4481,
4.8252, 4.9690, 4.8283, 4.7866, 4.8281, 4.8784, 4.5674, 4.4706, 4.3238,
4.6094, 4.3764, 4.7190, 4.2643, 4.8801, 4.5625, 4.5427, 4.8193, 4.8709,
4.4313, 4.5512, 4.4553, 5.2397, 4.6987, 4.9395, 4.5036, 4.7875, 4.7663,
4.9747, 4.5486, 4.6612, 4.5463, 4.9352, 4.9381, 4.4469, 4.8464, 4.5437,
4.7972, 4.9030, 4.7755, 4.6783, 4.4491, 4.5710, 4.3873, 4.5539, 4.6423,
4.7834, 4.8794, 4.9736, 4.5666, 4.2649, 4.3008, 4.4493, 4.5511, 4.5869,
4.8481], grad_fn=<NegBackward0>)
Train using the same data as before:
trainer = pl.Trainer(max_epochs=20)
#trainer = pl.Trainer(max_epochs=20, accelerator="cpu") # msn: needed on Mac due to float64 limitations on Apple Silicon
trainer.fit(model=npe, train_dataloaders=train_loader, val_dataloaders=val_loader);
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
--------------------------------------------------
0 | featurizer | Sequential | 74.6 K | train
1 | flow | Flow | 24.3 K | train
--------------------------------------------------
99.0 K Trainable params
0 Non-trainable params
99.0 K Total params
0.396 Total estimated model params size (MB)
89 Modules in train mode
0 Modules in eval mode
`Trainer.fit` stopped: `max_epochs=20` reached.
Get a test data sample, pass it through the feature extractor, and condition the flow density estimator on it. We get posterior samples by drawing from
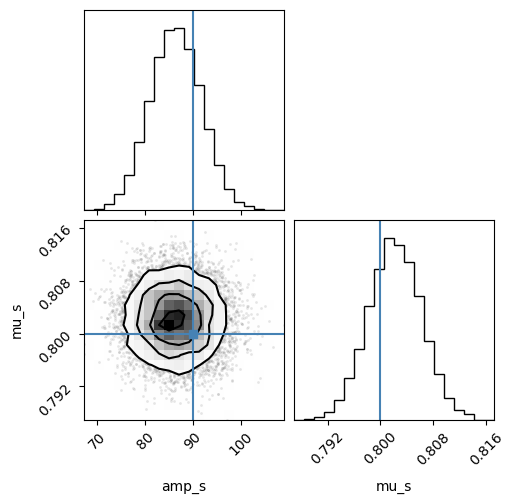
theta_test = np.array([90, 0.8])
x_test = bump_simulator(theta_test, y)
x_test_norm = (torch.Tensor(x_test) - x_mean) / x_std
context = npe.featurizer(x_test_norm).unsqueeze(0)
samples_test = npe.flow.sample(num_samples=10000, context=context) * theta_std + theta_mean
samples_test = samples_test.detach().numpy()
# Reshape the 3D array to 2D
num_samples = samples_test.shape[1]
data_2d = samples_test.reshape(num_samples, -1) # Reshape to (num_samples, 2) msn: not needed on Colab!
corner.corner(data_2d, labels=["amp_s", "mu_s"], truths=[90, 0.8]);
A more complicated example: distribution of point sources in a 2D image#
Finally, let’s look at a more complicated example, one that is closer to a typical application of SBI and where the likelihood is formally intractable.
The forward model simulates a map of point sources with mean counts drawn from a power law (Pareto) distribution. The distribution of the mean counts is given by the following equation:
where \(A\) is the amplitude (amp_b), \(s\) is the flux, and \(\beta\) is the exponent (exp_b). The fluxes are drawn from a truncated power law with minimum and maximum bounds, \(s_\text{min}\) and \(s_\text{max}\), respectively.
The number of sources is determined by integrating the power law distribution within the flux limits and taking a Poisson realization:
For each source, a position is randomly assigned within the box of size box_size. The fluxes are then binned into a grid with resolution number of bins in both x and y directions. The resulting map is convolved with a Gaussian point spread function (PSF) with a standard deviation of sigma_psf to account for the spatial resolution of the instrument.
The output is a 2D map of counts, representing the simulated observation of the point sources in the sky.
from scipy.stats import binned_statistic_2d
from astropy.convolution import convolve, Gaussian2DKernel
def simulate_sources(amp_b, exp_b, s_min=0.5, s_max=50.0, box_size=1., resolution=64, sigma_psf=0.01):
""" Simulate a map of point sources with mean counts drawn from a power law (Pareto) distribution dn/ds = amp_b * s ** exp_b
"""
# Get number of sources by analytically integrating dn/ds and taking Poisson realization
n_sources = np.random.poisson(-amp_b * (s_min ** (exp_b - 1)) / (exp_b - 1))
# Draw fluxes from truncated power law amp_b * s ** (exp_b - 1), with s_min and s_max as the bounds
fluxes = draw_powerlaw_flux(n_sources, s_min, s_max, exp_b)
positions = np.random.uniform(0., box_size, size=(n_sources, 2))
bins = np.linspace(0, box_size, resolution + 1)
pixel_size = box_size / resolution
kernel = Gaussian2DKernel(x_stddev=1.0 * sigma_psf / pixel_size)
mu_signal = binned_statistic_2d(x=positions[:, 0], y=positions[:, 1], values=fluxes, statistic='sum', bins=bins).statistic
counts = np.random.poisson(convolve(mu_signal, kernel))
return fluxes, counts
def draw_powerlaw_flux(n_sources, s_min, s_max, exp_b):
"""
Draw from a powerlaw with slope `exp_b` and min/max mean counts `s_min` and `s_max`. From:
https://stackoverflow.com/questions/31114330/python-generating-random-numbers-from-a-power-law-distribution
"""
u = np.random.uniform(0, 1, size=n_sources)
s_low_u, s_high_u = s_min ** (exp_b + 1), s_max ** (exp_b + 1)
return (s_low_u + (s_high_u - s_low_u) * u) ** (1.0 / (exp_b + 1.0))
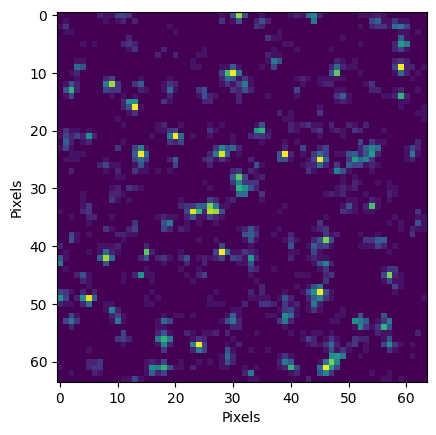
fluxes, counts = simulate_sources(amp_b=200., exp_b=-1.2)
plt.imshow(counts, cmap='viridis', vmax=20)
plt.xlabel("Pixels")
plt.ylabel("Pixels")
Text(0, 0.5, 'Pixels')
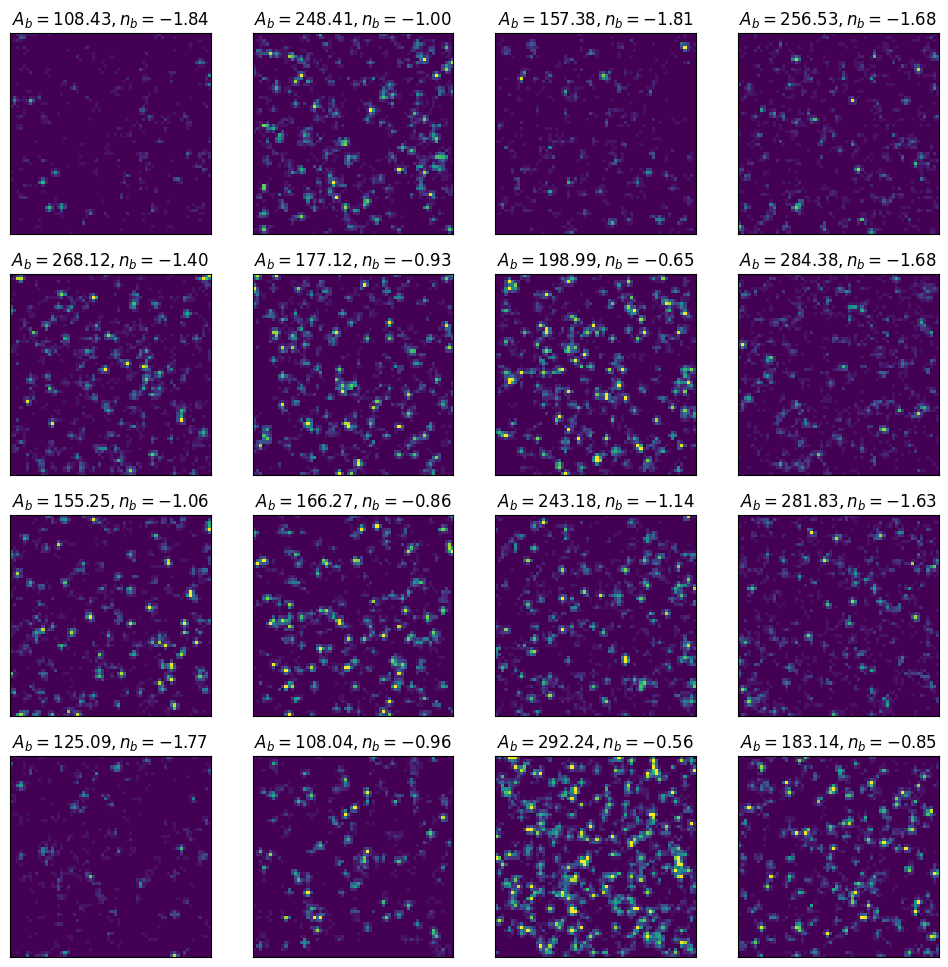
# Draw parameters from the prior
n_params = 16
amp_b_prior = (100., 300.)
exp_b_prior = (-2.0, -0.5)
amp_bs = np.random.uniform(amp_b_prior[0], amp_b_prior[1], n_params)
exp_bs = np.random.uniform(exp_b_prior[0], exp_b_prior[1], n_params)
# Plot the data samples on a grid
fig, axes = plt.subplots(4, 4, figsize=(12, 12))
for i, ax in enumerate(axes.flatten()):
fluxes, counts = simulate_sources(amp_b=amp_bs[i], exp_b=exp_bs[i])
im = ax.imshow(counts, cmap='viridis', vmax=20)
ax.set_title(f'$A_b={amp_bs[i]:.2f}, n_b={exp_bs[i]:.2f}$')
ax.set_xticks([])
ax.set_yticks([])
plt.show()
The Explicit Likelikood#
The (marginal) likelihood, which we would need to plug into something like MCMC, is computationally intractable! This is because it involves an integral over a cumbersome latent space, which consists of all possible number \(n\) of sources and their positions \(\{z\}=\{x, y\}_{i=1}^{n}\).
Let’s write this out formally:
Implicit inference: Neural posterior estimation#
Let’s use neural posterior estimation with a normalizing flow again. Get a training sample:
n_train = 30_000
# Sample from prior, then simulate
theta_samples = np.random.uniform(low=[10., -3.], high=[200., -0.99], size=(n_train, 2))
x_samples = np.array([simulate_sources(theta[0], theta[1])[1] for theta in tqdm(theta_samples)])
# Convert to torch tensors
theta_samples = torch.Tensor(theta_samples)
x_samples = torch.Tensor(x_samples)
# Normalize the data
x_mean = x_samples.mean(dim=0)
x_std = x_samples.std(dim=0)
x_samples = (x_samples - x_mean) / x_std
theta_mean = theta_samples.mean(dim=0)
theta_std = theta_samples.std(dim=0)
theta_samples = (theta_samples - theta_mean) / theta_std
100%|██████████| 30000/30000 [00:10<00:00, 2790.80it/s]
val_fraction = 0.1
batch_size = 128
n_samples_val = int(val_fraction * len(x_samples))
dataset = TensorDataset(x_samples, theta_samples)
dataset_train, dataset_val = random_split(dataset, [len(x_samples) - n_samples_val, n_samples_val])
train_loader = DataLoader(dataset_train, batch_size=batch_size, num_workers=8, pin_memory=True, shuffle=True)
val_loader = DataLoader(dataset_val, batch_size=batch_size, num_workers=8, pin_memory=True, shuffle=False)
Since we’re working with images, use a simple convolutional neural network (CNN) as the feature extractor. The normalizing flow will be conditioned on the output of the CNN.
class CNN(nn.Module):
""" Simple CNN feature extractor.
"""
def __init__(self, output_dim):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 8, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(8, 16, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 16 * 16, 64)
self.fc2 = nn.Linear(64, output_dim)
def forward(self, x):
x = x.unsqueeze(1) # Add channel dim
x = self.pool1(F.leaky_relu(self.conv1(x), negative_slope=0.02))
x = self.pool2(F.leaky_relu(self.conv2(x), negative_slope=0.02))
x = x.view(x.size(0), -1)
x = F.leaky_relu(self.fc1(x), negative_slope=0.01)
x = self.fc2(x)
return x
npe = NeuralPosteriorEstimator(featurizer=CNN(output_dim=32), d_context=32)
npe.loss(x_samples[:64], theta_samples[:64])
tensor([5.5472, 5.4650, 5.2634, 5.2259, 5.4311, 5.4464, 5.2569, 5.2601, 5.2231,
5.6663, 5.6888, 5.6201, 5.2845, 5.2401, 5.4838, 5.5989, 5.5505, 5.2108,
5.3182, 5.5351, 5.2221, 5.2659, 5.2454, 5.5654, 5.6308, 5.3478, 5.7694,
5.2209, 5.3496, 5.4248, 5.5198, 5.2646, 5.2557, 5.3036, 5.4230, 5.6174,
5.3109, 5.2547, 5.2582, 5.4802, 5.2518, 5.2179, 5.2548, 5.4662, 5.2859,
5.2461, 5.5553, 5.2576, 5.3641, 5.6228, 5.3387, 5.3764, 5.2950, 5.2379,
5.4209, 5.5746, 5.4005, 5.5264, 5.2809, 5.3875, 5.5117, 5.2231, 5.4146,
5.3383], grad_fn=<NegBackward0>)
trainer = pl.Trainer(max_epochs=15)
#trainer = pl.Trainer(max_epochs=15, accelerator="cpu") # msn: needed on Mac due to float64 limitations on Apple Silicon
trainer.fit(model=npe, train_dataloaders=train_loader, val_dataloaders=val_loader);
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
-------------------------------------------
0 | featurizer | CNN | 265 K | eval
1 | flow | Flow | 30.5 K | eval
-------------------------------------------
296 K Trainable params
0 Non-trainable params
296 K Total params
1.184 Total estimated model params size (MB)
0 Modules in train mode
88 Modules in eval mode
`Trainer.fit` stopped: `max_epochs=15` reached.
npe = npe.eval()
Get a test map, extract features, condition normalizing flow, extract samples.
params_test = np.array([15., -1.4])
x_test = simulate_sources(params_test[0], params_test[1])[1]
x_test_norm = (torch.Tensor(x_test) - x_mean) / x_std
context = npe.featurizer(x_test_norm.unsqueeze(0))
samples_test = npe.flow.sample(num_samples=10000, context=context) * theta_std + theta_mean
samples_test = samples_test.detach().numpy()
print(samples_test.shape)
#corner.corner(samples_test, labels=["amp", "exp"], truths=params_test);
# Reshape the 3D array to 2D
num_samples = samples_test.shape[1]
data_2d = samples_test.reshape(num_samples, -1) # Reshape to (num_samples, 2) msn: not needed on Colab!
print(data_2d.shape)
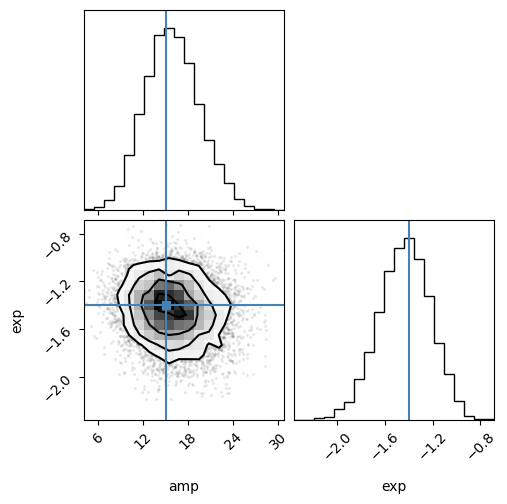
corner.corner(data_2d, labels=["amp", "exp"], truths=params_test);
(1, 10000, 2)
(10000, 2)
Test of Statistical Coverage#
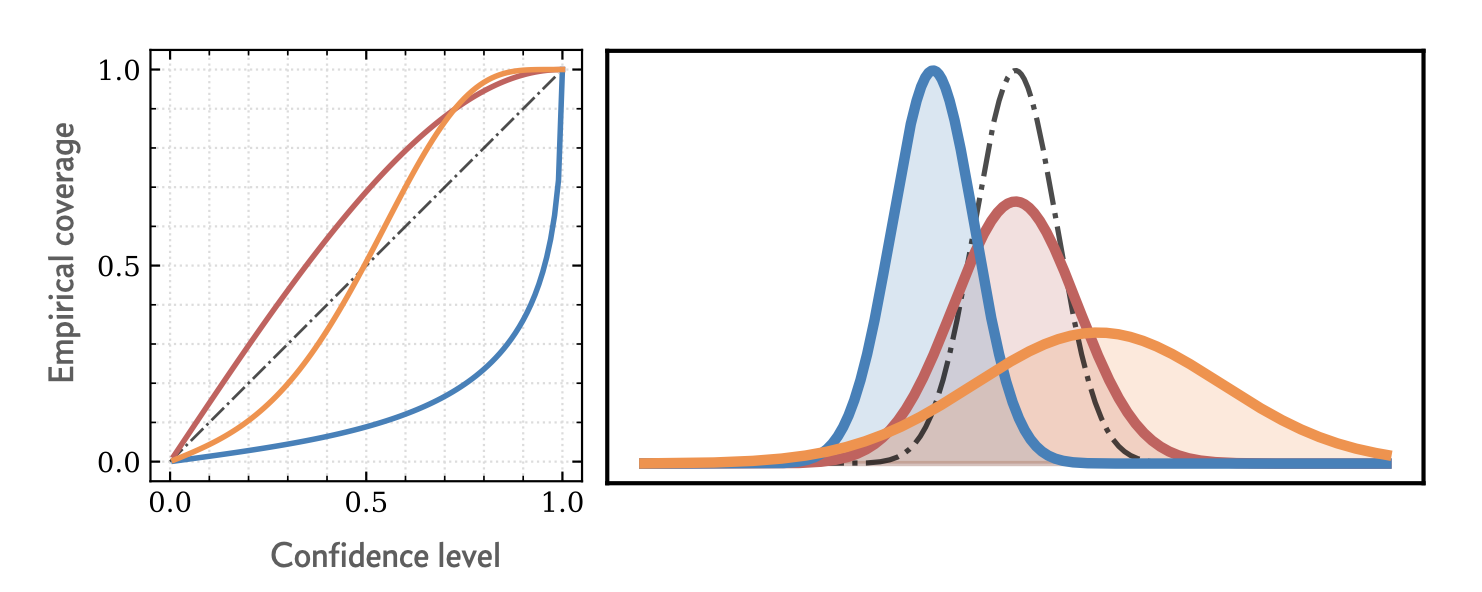
Figure from https://arxiv.org/abs/2209.01845
We can do some checks to make sure that our posterior has the correct statistical interpretation. In particular, let’s test the posterior statistical coverage by evaluating how well the Highest Posterior Density (HPD) intervals capture the true parameter values.
The Highest Posterior Density (HPD) interval is a region in the parameter space that contains the most probable values for a given credible mass (e.g., 95% or 99%). In other words, it is the shortest interval that contains the specified credible mass of the posterior distribution. This is one of summarizing a posterior distribution.
Nominal coverage is the probability, or the proportion of the parameter space, that the HPD interval is intended to contain. For example, if the nominal coverage is 0.95, the HPD interval should theoretically contain the true parameter value 95% of the time.
Empirical coverage is the proportion of true parameter values that actually fall within the HPD interval, based on a set of test cases or simulations.
For a perfectly calibrated posterior estimator, empirical coverage = nominal coverage for all credibility levels.
n_test = 200 # How many test samples to draw for coverage test
# Get samples
x_test = torch.Tensor([simulate_sources(params_test[0], params_test[1])[1] for _ in range(n_test)])
x_test_norm = (torch.Tensor(x_test) - x_mean) / x_std
# and featurize
context = npe.featurizer(x_test_norm)
# Get posterior for all samples together in a batch
samples_test = npe.flow.sample(num_samples=1000, context=context) * theta_std + theta_mean
samples_test = samples_test.detach().numpy()
/tmp/ipykernel_80963/4001163492.py:4: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at /pytorch/torch/csrc/utils/tensor_new.cpp:254.)
x_test = torch.Tensor([simulate_sources(params_test[0], params_test[1])[1] for _ in range(n_test)])
def hpd(samples, credible_mass=0.95):
"""Compute highest posterior density (HPD) of array for given credible mass."""
sorted_samples = np.sort(samples)
interval_idx_inc = int(np.floor(credible_mass * sorted_samples.shape[0]))
n_intervals = sorted_samples.shape[0] - interval_idx_inc
interval_width = np.zeros(n_intervals)
for i in range(n_intervals):
interval_width[i] = sorted_samples[i + interval_idx_inc] - sorted_samples[i]
hdi_min = sorted_samples[np.argmin(interval_width)]
hdi_max = sorted_samples[np.argmin(interval_width) + interval_idx_inc]
return hdi_min, hdi_max
hpd(samples_test[0, :, 0], credible_mass=0.2)
(np.float32(13.387672), np.float32(15.186882))
p_nominals = np.linspace(0.01, 0.99, 50)
contains_true = np.zeros((2, n_test, len(p_nominals)))
for i_param in range(2):
for i, sample in enumerate(samples_test[:, :, i_param]):
for j, p_nominal in enumerate(p_nominals):
hdi_min, hdi_max = hpd(sample, credible_mass=p_nominal)
if hdi_min < params_test[i_param] < hdi_max:
contains_true[i_param, i, j] = 1
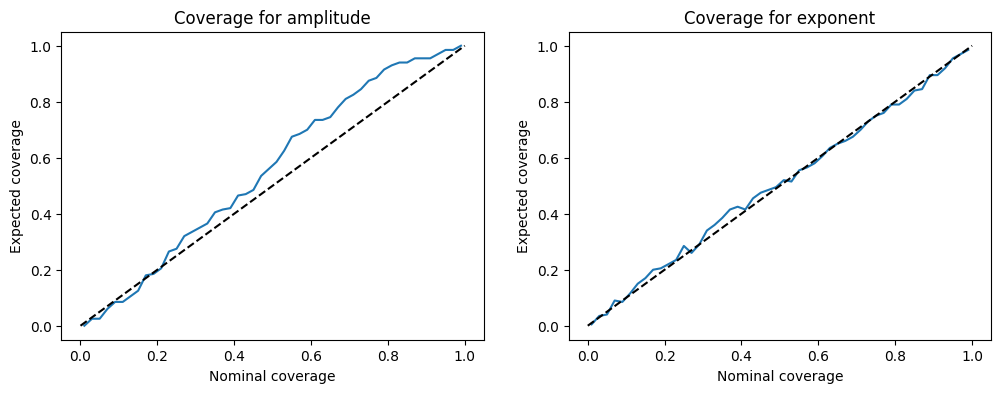
# Make two plots, one for each parameter
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
ax[0].plot(p_nominals, contains_true[0].sum(0) / n_test)
ax[0].plot([0, 1], [0, 1], color="black", linestyle="--")
ax[0].set_xlabel("Nominal coverage")
ax[0].set_ylabel("Expected coverage")
ax[0].set_title("Coverage for amplitude")
ax[1].plot(p_nominals, contains_true[1].sum(0) / n_test)
ax[1].plot([0, 1], [0, 1], color="black", linestyle="--")
ax[1].set_xlabel("Nominal coverage")
ax[1].set_ylabel("Expected coverage")
ax[1].set_title("Coverage for exponent")
Text(0.5, 1.0, 'Coverage for exponent')
Acknowledgments#
Initial version: Mark Neubauer
Modified from the following lecture
Code Heavily Inspired by the Following Repositories
© Copyright 2026